 七月NLP课程笔记(7)-词向量与相关应用
七月NLP课程笔记(7)-词向量与相关应用
ref: http://blog.csdn.net/zxm1306192988/article/details/78697740
# 保证词的相似性
如果只是给每个词设置一个索引下标来对词进行编码,无法体现词与词之间的相关性。
希望编码能够保留词之间的关系: 近义的词,计算出来的距离较近,反义的词,距离较远……
# 基于词典
在英语中 nltk 库 ,包含此类词典。 例如,猫的上位词(形容猫的词语,如 动物,有毛,吃肉……),美丽的同义词(漂亮,好看……) 通过专家根据背景知识来人为的构造。
存在问题:
- 不能分辨细节的差别
- 需要大量人为劳动
- 有主观性
- 无法发现新词
- 难以精确计算词之间的相似性
# 离散表示
# 不考虑顺序
onehot
语料库: John likes to watch movies. Mary likes too. John also likes to watch football games.
词典: {“John”:1,”likes”:2,”to”:3,”watch”:4,”movies”:5,”also”:6,”football”:7,”games”:8,”Mary”:9,”too”:10}
One-hot 表示 :
John:[1,0,0,0,0,0,0,0,0,0]
likes:[0,1,0,0,0,0,0,0,0,0]
…
too:[0,0,0,0,0,0,0,0,0,1]
2
3
4
词典包含10个单词,每个单词有唯一索引 在词典中的顺序和在句子中的顺序没有关联
bag of words
文档的向量表示可以直接将各词的词向量表示加和:
John likes to watch movies. Mary likes too. ->
[1,2,1,1,1,0,0,0,1,1]
John also likes to watch football games. ->
[1,1,1,1,0,1,1,1,0,0]
2
3
4
句子的向量表示为,对应词典,每个位置上的词在这个句子中所出现的次数。 每个词是One-hot表示,整个句子就是 Bag of Words 表示形式。 丢失了词语在句子中的前后顺序信息。
** 词权重 ** 可用tf-idf衡量词权重。(没有考虑词的出现顺序)
# 考虑顺序:N-gram

# 离散表示的问题
- 无法衡量词向量之间的关系
- 太稀疏,很难捕捉文本的含义
- 词表维度随着语料库增长膨胀
- n-gram 次序列随语料库膨胀更快
# 分布式表示
如果两个词的上下文相似,那么这两个词也是相似的。用一个词附件的其他词,来表示该词。
# 共现矩阵(Cocurrence matrix)
有一个窗口大小(例如,取1则表示考虑该单词与其左右各1个单词之间的共现关系,一般设为 5~10)。
矩阵是对称的:
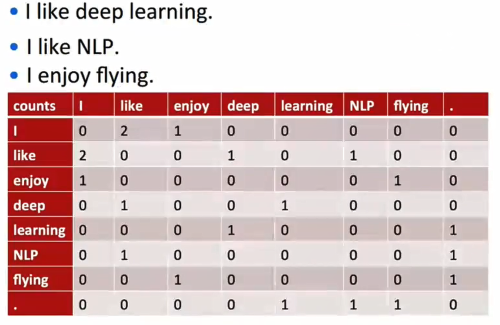
可以取矩阵里的一行,作为表示该单词的向量。
存在的问题:
- 向量维数随着词典大小线性增长
- 存储整个词典的空间消耗非常大
- 一些模型如文本分类模型会面临稀疏性问题
- 模型会欠稳定(新加语料后,向量就变了)
所以我们需要构造低维稠密向量作为词的分布式表示(25~1000维).
# SVD降维
用SVD对共现矩阵向量做降维。
关于SVD的介绍:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
import numpy as np
import matplotlib.pyplot as plt
la=np.linalg
words=["I","like","enjoy","deep","learning","NLP","flying","."]
X=np.array([
[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]
])
U,s,Vh=la.svd(X,full_matrices=False)
plt.axis([-0.8,0.2,-0.8,0.8])
for i in range(len(words)):
plt.text(U[i,0],U[i,1],words[i])
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
SVD降维存在的问题:
- 计算量随语料库和词典增长膨胀太快,对 X(n,n) 维的矩阵,计算量 O(n3)。而对大型的语料库,n~400k,语料库大小 1~60B token。
- 难以为词典中新加入的词分配词向量
- 与其他深度学习模型框架差异大
# NNLM:神经网络语言模型
把神经网络中的模型最优化过程,转换成求解词向量的过程。

窗口长度为n-1,且是单向的,也就是说考虑当前词和它之前的n-1个词。 目标函数是在前n-1个词出现的条件下当前词出现的概率。 使得目标函数最大。
运用神经网络来计算概率P。
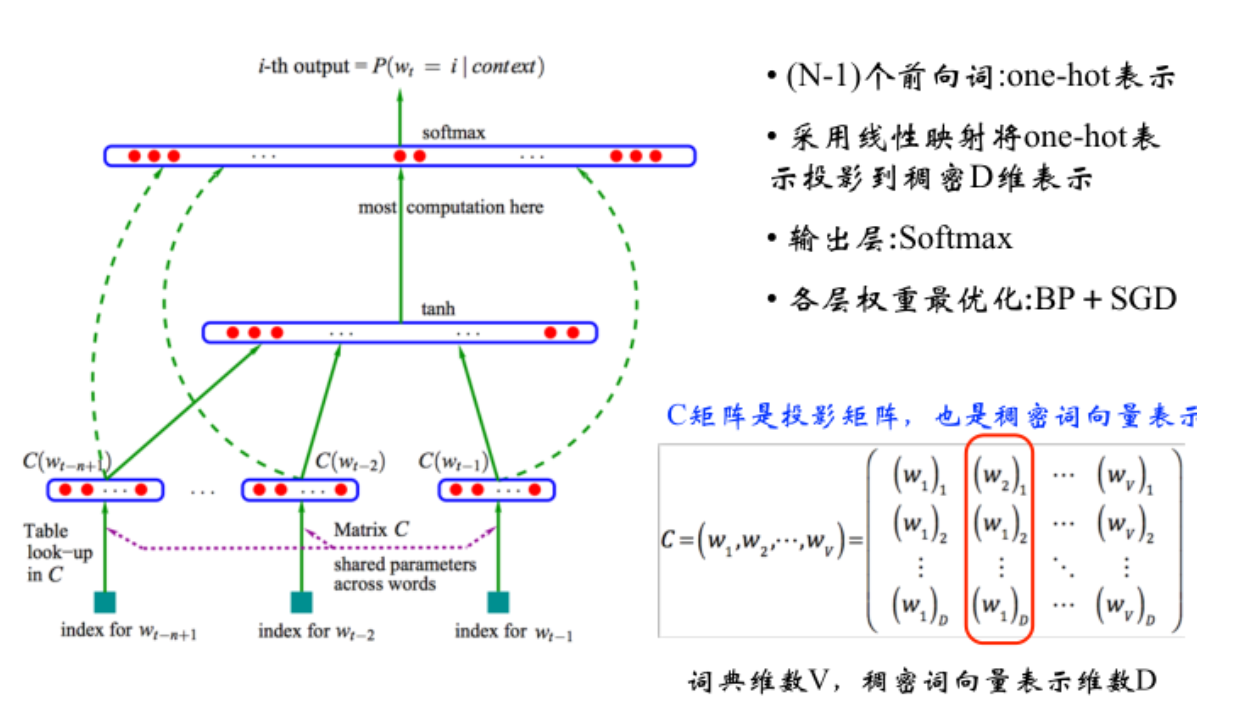
如图所示,最初输入的是前n-1个词,每个词用one-hot表示。每个词的one-hot表示(假设是180000的向量,即,词典共有80000个词),乘以一个投影矩阵C。矩阵C的大小为80000500,也就是说每个词与矩阵相乘后,得到1*500的向量,作为该词的最终词向量。
将每个单词的词向量进行拼接,放入有一个隐藏层的人工神经网络,隐藏层神经元个数一般为300或500,激活函数为 tanh 双曲正切 ,softmax是线性分类器,得到 词典个数维(举例中 应该是80000维,因为有80000个词) 的概率向量,每个位置表示是这个单词的概率,与已知的输出计算交叉熵(Cross Entropy)损失,不断训练整个模型。
而这里的关键是矩阵C,通过训练模型达到最优后,得到的矩阵C即为词典中各个词的词向量表示。
缺点:训练神经网络需要大量数据和计算。
# word2vec
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。 CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。 CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。 这里假设滑窗尺寸为1
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
ref http://www.sohu.com/a/128794834_211120 http://blog.csdn.net/mylove0414/article/details/61616617
# word2vec:CBOW (连续词袋)
进行了一些简化,去掉隐层,采用前后双向的上下文窗口,但是不考虑词序。因此之前将各个词向量拼接成很长向量的过程,就变成了将各个词向量相加。
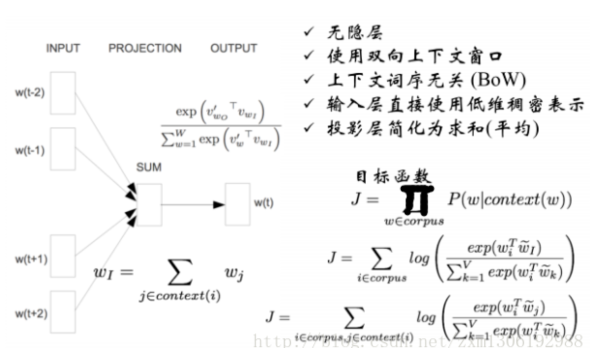
最后输出是词典中每个词的概率. 输出向量有80000维(词典长度),映射层为各个单词向量相加,为500维,则从映射层到输出层需要一个500*80000维的权重,此处的计算量过大,所以继续采用以下方法优化。
** 优化方法:层级编码 **
使用Huffman Tree对输出层的词典进行编码。 (Huffman Tree 参见 https://www.cnblogs.com/kubixuesheng/p/4397798.html)
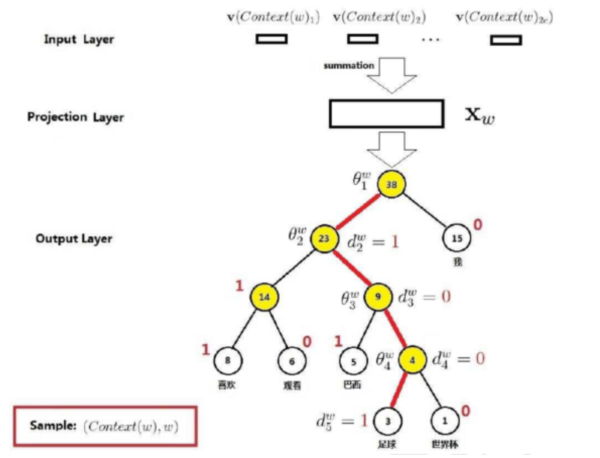
使用 Huffman Tree 来编码输出层的词典 只需要计算路径上所有非叶子节点词向量的贡献即可 计算量降为树的深度 V=> log2(V) 此时中间的单词为 w(t) ,而映射层输入为 pro(t)=v(w(t-2))+v(w(t-1))+v(w(t+1))+v(w(t+2))
假设此时的单词为“足球”,即 w(t)=”足球” ,则其Huffman码可知为 d(t)=”1001” ,那么根据Huffman码可知,从根节点到叶节点的路径为 “左右右左”,即从根节点开始,先往左拐,再往右拐2次,最后再左拐。
既然知道了路径,那么就按照路径从上往下依次修正路径上各节点的中间向量。在第一个节点,根据节点的中间向量 Θ(t,1) 和 pro(t) 进行逻辑分类。如果分类结果显示为0,则表示分类错误(应该向左拐,即分类到1),则要对 Θ(t,1) 进行修正,并记录误差量。
接下来,处理完第一个节点之后,开始处理第二个节点。方法类似,修正 Θ(t,2) ,并累加误差量。接下来的节点都以此类推。
在处理完所有节点,达到叶节点之后,根据之前累计的误差来修正词向量 v(w(t))。
这样,一个词w(t)的处理流程就结束了。如果一个文本中有N个词,则需要将上述过程在重复N遍,从w(0)~w(N-1)。
** 优化方法:负例采样 **
工业界用负例采样比较多。
从映射层到输出层,对负样本进行负例采用,减小权重矩阵大小,和输出概率向量大小。

# word2vec:Skip-Gram
skip-gram输入输出相反,是从一个词推出其临近的词。
大型语料中skip-gram效果往往更好。
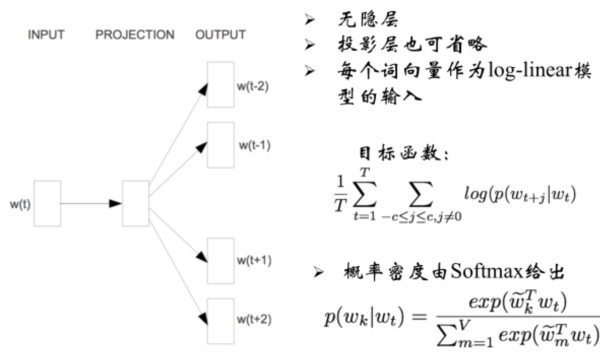
# word2vec:存在的问题
- 对每个 local context window (即只考虑了某个单词左右的上下文)单独训练,没有利用包含在 global co-currence(没有考虑全局共现) 矩阵中的统计信息。
- 对多义词无法很好的表示和处理,因为使用了唯一的词向量。(如 Apple的多义)
另外 还有一种Glove方法,也可生成词向量。 https://nlp.stanford.edu/projects/glove/
# 总结
离散表示
- One-hot representation ,Bag of words Unigram 语言模型
- N-gram 词向量表示和语言模型
- 共现矩阵的行(列)向量作为词向量
分布式连续表示
- 共现矩阵的SVD降维的低维词向量表示
- Word2Vec :CBOW Model
- Word2Vec:Skip-Gram Model
# 资料
** google word2vec **
❖地址 https://code.google.com/archive/p/word2vec/ 墙内用户请戳https://github.com/dav/word2vec
❖ 安装步骤
git clone https://github.com/dav/word2vec
cd word2vec/src
Make
2
3
试试./demo-word.sh 和./demo-phrases.sh
python常用的库 :gensim
**Word2vec+CNN做文本分类 ** 论文详见《Convolutional Neural Networks for Sentence Classification》 http://arxiv.org/abs/1408.5882
Theano完成的代码版本: https://github.com/yoonkim/CNN_sentence
TensorFlow改写的代码版本: https://github.com/dennybritz/cnn-text-classification-tf 添加 分词和 中文词向量映射之后,可用于中文文本分类(情感分析)
维基百科词向量构建: 基于维基百科数据,训练word2vec https://www.zybuluo.com/hanxiaoyang/note/472184
搜狗全网新闻语料地址 :http://www.sogou.com/labs/resource/ca.php
** sense2vec: ** word2vec模型的问题在于词语的多义性。比如duck这个单词常见的含义有 水禽或者下蹲,但对于 word2vec 模型来说,它倾向于将所有概念做归一化 平滑处理,得到一个最终的表现形式。
我们结合上下文和标签(例如,词性、具体分类等),会有更好的处理结果
用Spacy和word2vec结合,完成sense2vec https://github.com/explosion/sense2vec
** doc2vec: ** Doc2vec是基于Word2vec的基础上发展而来的方法,它可以将一段句子表征为实数值向量。 http://cs.stanford.edu/~quocle/paragraph_vector.pdf http://www.dataguru.cn/article-9478-1.html http://blog.csdn.net/lenbow/article/details/52120230