 KBQA | Core Techniques of Question Answering Systems over Knowledge Bases: a Survey
KBQA | Core Techniques of Question Answering Systems over Knowledge Bases: a Survey
论文地址:https://link.springer.com/article/10.1007/s10115-017-1100-y
# 摘要
语义网中包含大量的信息,以知识库的形式存储。KBQA系统可以帮助人们获取这些信息。构建KBQA系统时,面临许多挑战,通常需要结合自然语言处理、信息检索、机器学习和语义网络等多种技术。本文综述了目前基于流行的测评基准QALD的各个KBQA系统所使用的技术。本文将KBQA分成多个阶段,综述每个阶段的技术,同时探讨各项技术的优缺点。此外,也指出了基于WebQuestions和SimpleQuestions这两个流行的基准的QA系统所用到的技术。
# Introduction
QA系统有多种:对数据库的、对自然文本的、对知识库的……随着RDF和SPARQL的出现,KBQA成为研究热点。
在本文中,将KBQA分成五大子任务:问题分析、短语映射、消歧、查询构建、多个知识源上的查询。将描述、分类、比较各个KBQA系统中用到的技术。本文聚焦于3个数据源/评价基准:QALD(主要)、WebQuestions和SimpleQuestions。
# 三大流行评测基准简介
QALD (Question Answering over Linked Data) 其实并不是一个评测基准,而是一系列的比赛,已有6届,每届中会有一个任务是基于DBpedia的QA。
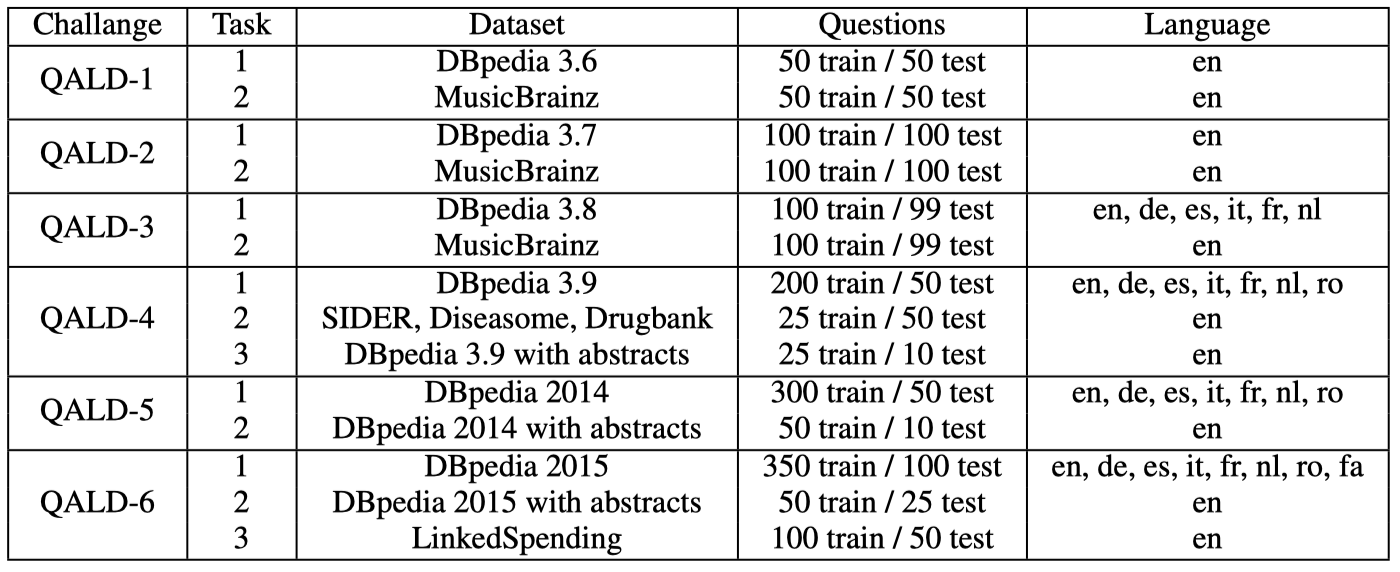
# 数据集
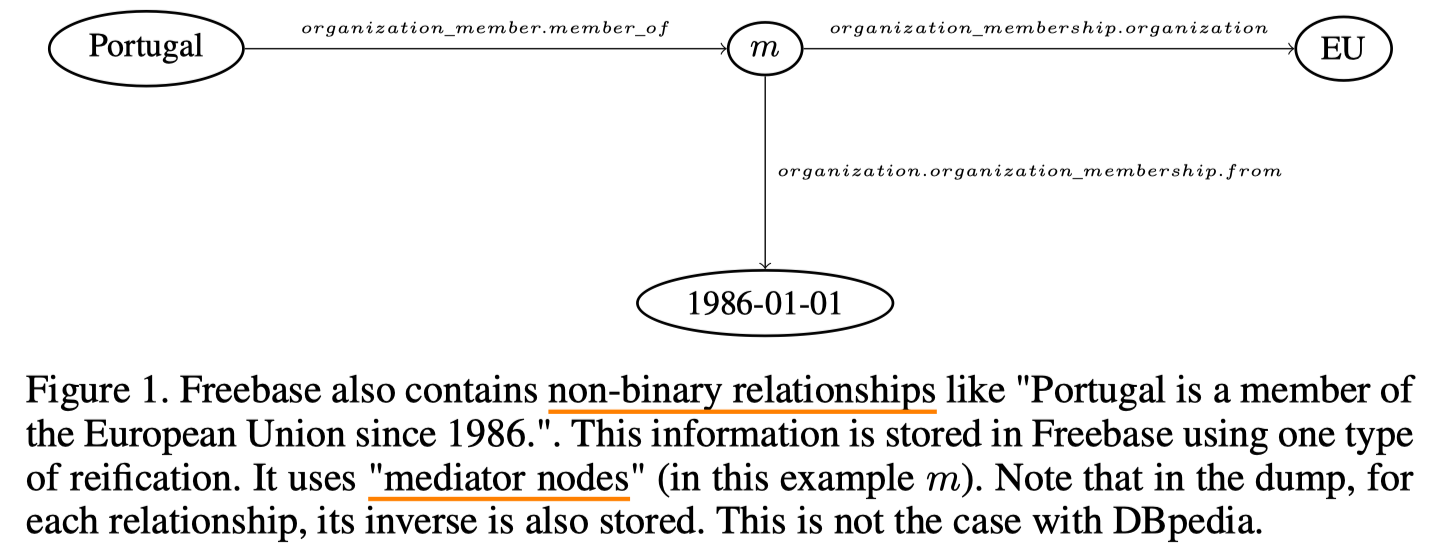
WebQuestions(以下简写为WQ)和SimpleQuestions (以下简写为SQ)是基于Freebase的,QALD则是基于DBpedia的。两个KB主要区别是,FB包含二元和非二元关系(例如时序关系,通过添加一个mediator节点来表示,见下图),而DBpedia只包含二元关系。此外,对每个关系,FB同时还保存了该关系的反向。
DBpedia大概有40w个三元组,而Freebase有19亿个三元组(考虑到Freebase中的mediator和反向,两者信息量基本差不多)。
# 问句
WQ包含约6k个问句,SQ包含10w个问句,而QALD规模小很多,约50-250个问句,所以QALD不利于做监督学习。
SQ和QALD对每个问句都有SPARQL表示,而WQ只是标示出了答案,有第三方的数据集给出了WQ的SPARQL表示。
# 评价指标
precision、recall和F1值。
给定问题q,Precision = 系统给出的答案中正确的个数 / 系统给出的答案总数, Recall = 系统给出的答案中正确的个数 / 总的正确答案数。
例如,问句 三原色,答案是红绿蓝,如果系统只给出了绿和蓝,Precision是1,Recall是 2/3。
F值则是2*P*R / (P+R) 来计算得到。
评价指标包含micro和macro两种,micro只根据系统回答了的问题,取各个问题p、r的平均得到系统的p、r,未回答的问题不计入,而macro则计入所有的问题。本文中使用macro指标。
此外,系统运行耗时也是一个评价指标。
# QA系统的选择
本文筛选用于分析的QA系统时,首先选出了参加QALD比赛,以及引用了QALD文章的系统,然后进行筛选,例如,滤除了一些只能回答形式化问题的系统。
# 五大任务
概述下五大任务。 1)问句分析,主要是NLP的基础分析:判断问句类型、NER、关系分类、依存句法等。 2)短语映射,从问句中找到的短语s,在知识库中找到对应的资源(可能是实体、关系) 3)消歧,对之前的映射进行消歧 4)查询构建,也就是生成SPARQL语句,用于查询KB。 5)查询多个知识源,当问题需要从多个KB中进行搜索才能找到完整答案时。
以上五个只是一种总结归纳,并不意味着所有KBQA系统都严格按照上面五个任务来划分。
# 问句分析
问句分析,又可以分为下面的几个类型。
# NER
可使用现有的NLP工具包进行NER,局限是只限于某些特定领域(人名地名等)。还可使用Ngram的方式,将Ngram结果作为各个实体,与KB进行比较。如果有现成的Entity Linking工具,可以直接完成实体识别+与知识库的映射。
# 切分和 POS tagging
先对句子进行POS标注,有了POS tag,可以辅助进行句子的切分(切出表示实体、关系的短语)。可通过人工构建规则的方式(例如正则表达式等),也可以通过标注训练数据+机器学习的方式。
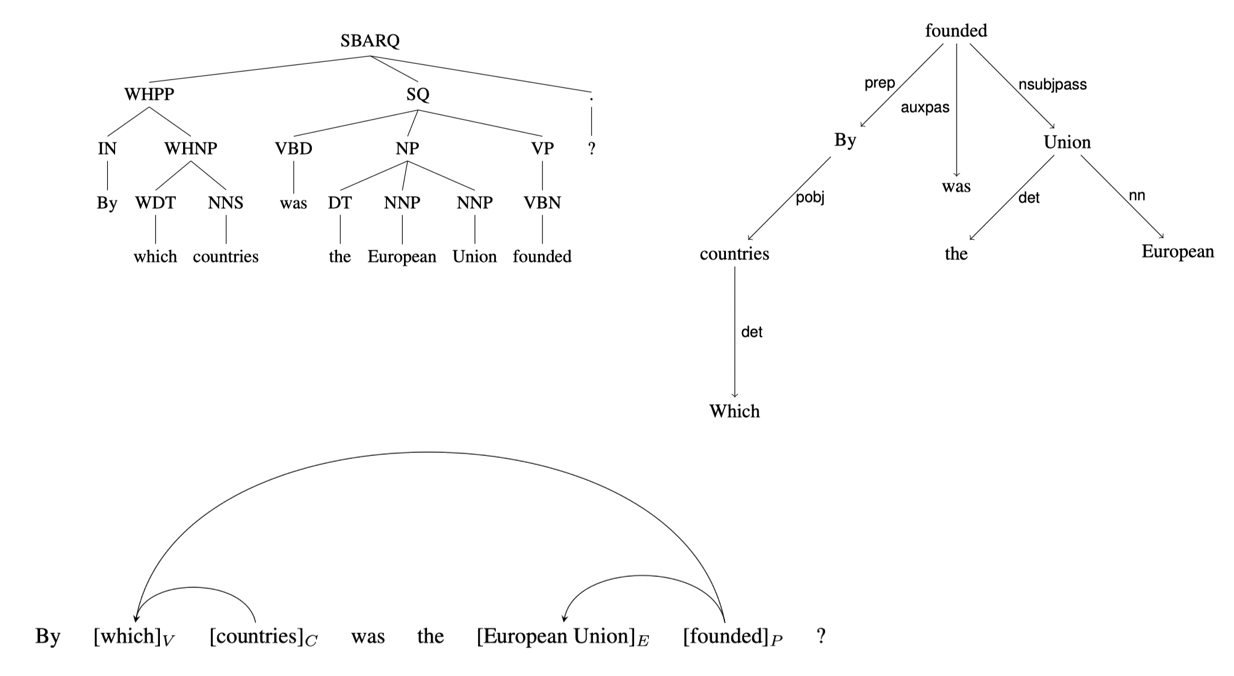
# 依存分析
依存分析可以识别出句子中各个块之间的关系。parser要基于某种形式化的语法来做解析,语法包括符号以及将符号组合起来的规则。不同的KBQA系统,有时使用了不同的依存分析语法。
下图展示了几种不同的解析表示方式。
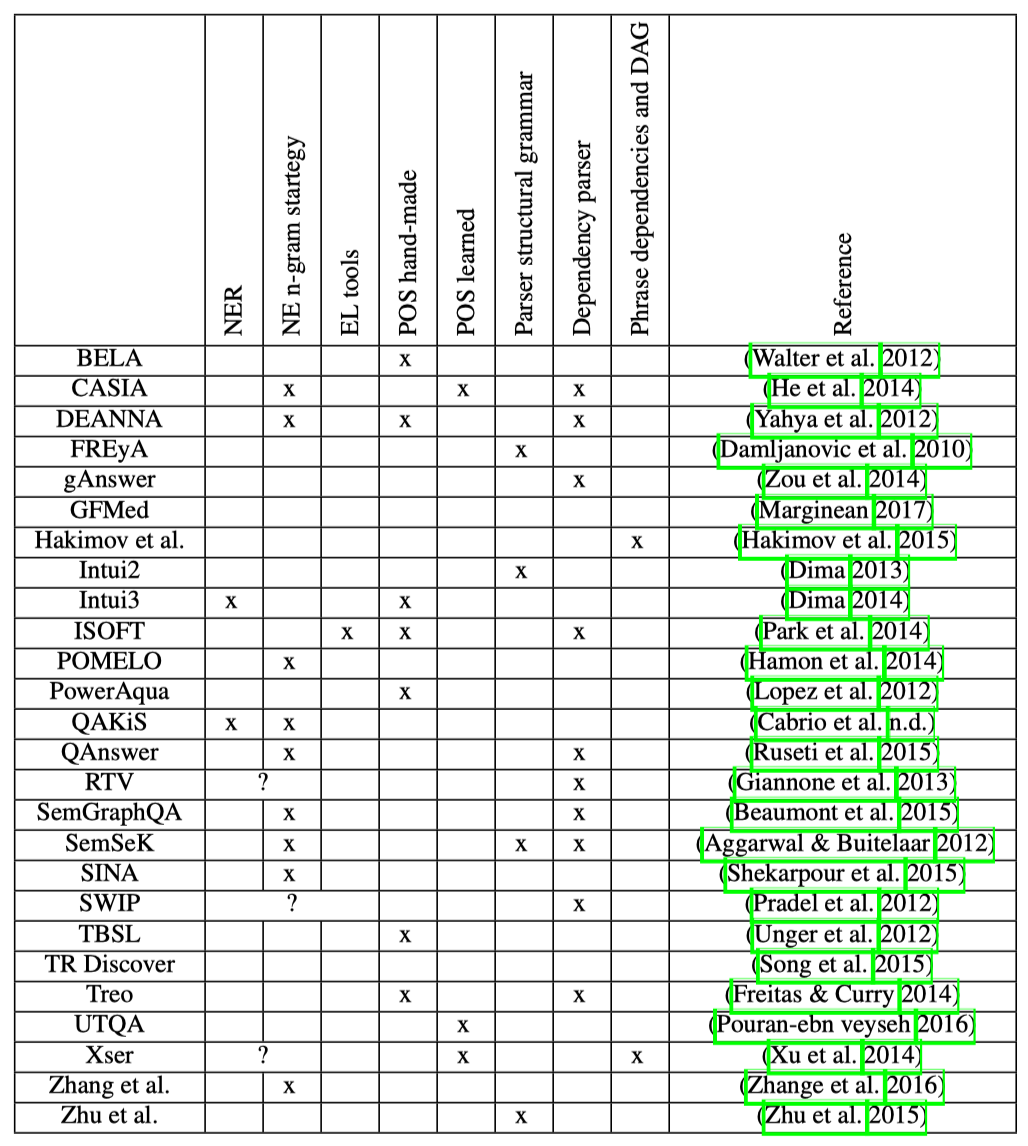
# 小结
下图展示了参与分析的KBQA系统所使用到的技术。
# 短语映射
给定一个短语s,想要在KB中找到它对应的实体/关系/类。
KB中,资源记作r,每个资源有对应的label,所以我们的目标是给定s,找到label与s相等或包含s的r。
为了能够快速进行搜索,需要对KB构建索引,可使用某些三元组数据库(例如说virtuoso)内置的索引功能,或者采用LUcene外部搜索工具。
但在映射时,有一些要注意的问题:一是s可能存在拼写错误或者单复数等形式,导致字面符号不完全一致;二是存在文字书写几乎不相关,但语义非常相似的,例如EU对应欧盟,married对应spouse等。这两个问题非常重要。
第一个问题,可通过计算字符串相似度,or 模糊搜索 or 英文的stemming词干化,来解决拼写错误或单复数的问题。
第二个问题涉及语义相似度,主要有以下解决思路:
1)词库。例如借助WordNet和Wiktionary,或者专门的一个同义词库PATTY,可将s扩展成多个同义词,拿多个同义词去KB中搜索。带来的一个坏处是由于匹配到了更多的内容,给消歧增大了计算量。
2)重定向。开发知识库的sameAs关系,为一个实体增加多个sameAs实体,这样就便于匹配到了。
3)从文本中抽取。例如已知kb中的三元组x,r,y,拿着x,y去文本中,找他俩出现的位置,夹在之间的文本很可能就是关系r对应的文本表示。大致依照这种思路,找到文本与KB资源的对应关系。
4)词向量方式。借助word2vec等词向量,找到同义词,或者计算相似度。
此外,有部分工具直接提供了短语映射功能,例如DBpedia Lookup、WikiPedia Miner Tool等。
# 小结
KBQA系统及其用到的方法,可见下图。
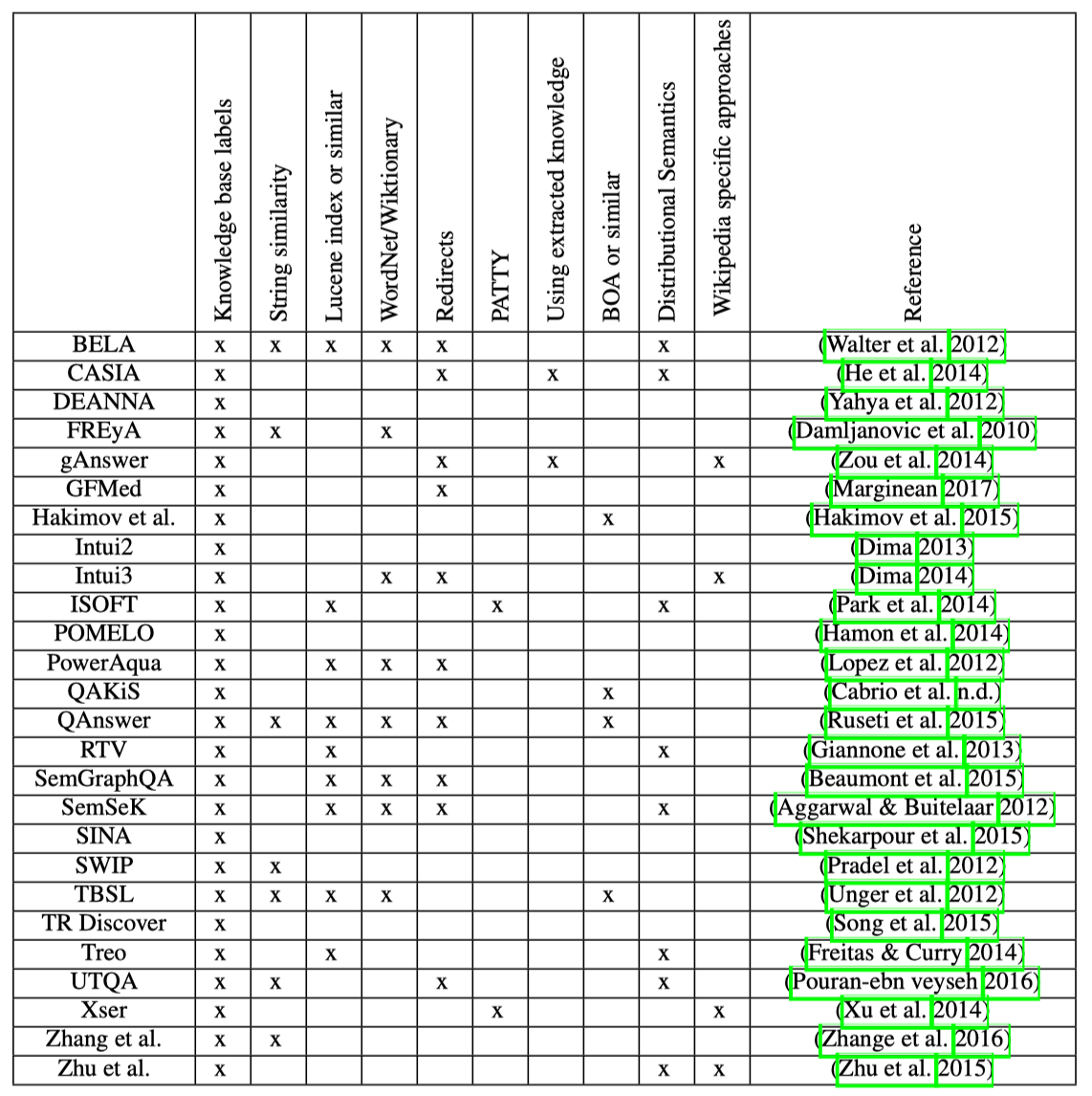
这里也涉及到p和r两个指标之间的取舍问题:更少的匹配可以提升precision,更多的匹配可以提升recall。
# 消歧
之前的两步操作,都可能产生歧义:切分和依存分析时会有歧义,将短语与KB进行映射时也会有歧义。
# 本地消歧
主要通过两种特征来辅助消歧。一是字符串或语义相似度,用来对多个候选答案进行排序。二是一些类型一致性检查,用来排除某些候选答案。之所以叫做“本地”,是因为只针对直接关联的这两个资源进行检查,不涉及其他资源,所以可直接本地进行,速度较快,但缺点是本地信息较少,有时不包含类型等信息,一致性检查就没法做。
例如,“谁是指环王的导演”,由于“导演”包含领域信息-电影,所以指环王的类型也应该是电影。但如果指环王不包含领域信息,这种一致性检查就没法做了。