 Stanford CoreNLP 快速上手
Stanford CoreNLP 快速上手
# 功能简介
Stanford CoreNLP 提供了一系列自然语言处理工具。可以进行 词干提取、POS tagging(词类/词性标注)、命名实体识别(公司、人名、日期)、将数值标准化、依存句法分析、共指消解、情感分析、关系抽取等。

下载地址 https://stanfordnlp.github.io/CoreNLP/index.html
支持英文、中文等多种语言,可下载核心工具包以及各种语言的模型文件。
工具包由 Java 写成,但可通过命令行、Java API、第三方API、web服务等多种方式来访问,因此可适配于使用各种语言编写的系统。
# 使用方法
官方使用说明 https://stanfordnlp.github.io/CoreNLP/corenlp-server.html 提供了对下载安装,以及命令行、Java API、web service等多种模式的使用说明。
这里记录一下使用 中文、web service的方式。
1) 将下载的中文模型文件夹里的内容(包括StanfordCoreNLP-chinese.properties文件 以及edu等文件夹) ,拷贝到corenlp的根目录下。
2) 运行如下命令启动服务。(可指定端口和超时,指定预加载哪些模型)
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -serverProperties StanfordCoreNLP-chinese.properties -port 9000 -timeout 15000
3)浏览器访问 localhost:9000 可以使用 web 界面。
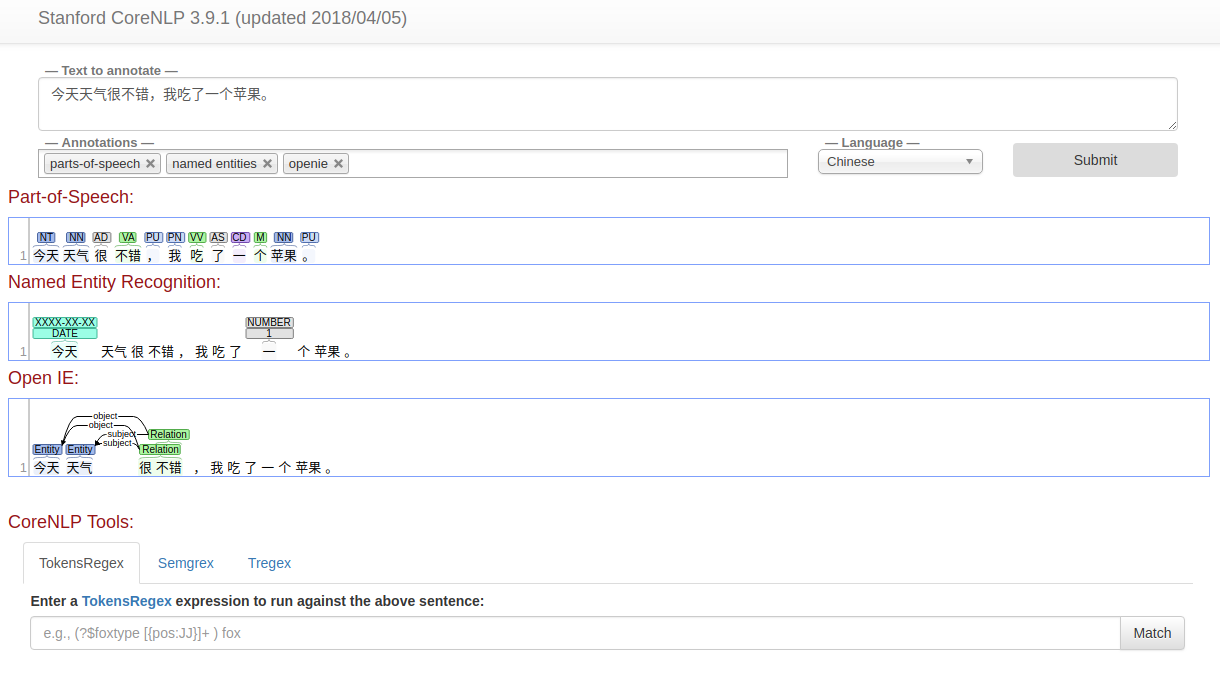
Stanford 的官方文档中,对于在其他编程语言中使用 CoreNLP、生产环境中部署 CoreNLP 等方面,都有相应介绍,比较详细,不再赘述。
# nltk + coreNLP 使用体验
python 自然语言工具包 nltk 提供了对 Stanford CoreNLP 的支持,可以在 python 中直接通过 nltk 来调用 CoreNLP,也是通过 web service的方式(所以调用前,需要单独开启 CoreNLP 的server),但好处在于调用很方便,不用自己处理各种http接口了。
详细参见 https://github.com/nltk/nltk/wiki/Stanford-CoreNLP-API-in-NLTK
英文:
>>> from nltk.parse import CoreNLPParser
# Lexical Parser
>>> parser = CoreNLPParser(url='http://localhost:9000')
# Parse tokenized text.
>>> list(parser.parse('What is the airspeed of an unladen swallow ?'.split()))
[Tree('ROOT', [Tree('SBARQ', [Tree('WHNP', [Tree('WP', ['What'])]), Tree('SQ', [Tree('VBZ', ['is']), Tree('NP', [Tree('NP', [Tree('DT', ['the']), Tree('NN', ['airspeed'])]), Tree('PP', [Tree('IN', ['of']), Tree('NP', [Tree('DT', ['an']), Tree('JJ', ['unladen'])])]), Tree('S', [Tree('VP', [Tree('VB', ['swallow'])])])])]), Tree('.', ['?'])])])]
# Parse raw string.
>>> list(parser.raw_parse('What is the airspeed of an unladen swallow ?'))
[Tree('ROOT', [Tree('SBARQ', [Tree('WHNP', [Tree('WP', ['What'])]), Tree('SQ', [Tree('VBZ', ['is']), Tree('NP', [Tree('NP', [Tree('DT', ['the']), Tree('NN', ['airspeed'])]), Tree('PP', [Tree('IN', ['of']), Tree('NP', [Tree('DT', ['an']), Tree('JJ', ['unladen'])])]), Tree('S', [Tree('VP', [Tree('VB', ['swallow'])])])])]), Tree('.', ['?'])])])]
# Neural Dependency Parser
>>> from nltk.parse.corenlp import CoreNLPDependencyParser
>>> dep_parser = CoreNLPDependencyParser(url='http://localhost:9000')
>>> parses = dep_parser.parse('What is the airspeed of an unladen swallow ?'.split())
>>> [[(governor, dep, dependent) for governor, dep, dependent in parse.triples()] for parse in parses]
[[(('What', 'WP'), 'cop', ('is', 'VBZ')), (('What', 'WP'), 'nsubj', ('airspeed', 'NN')), (('airspeed', 'NN'), 'det', ('the', 'DT')), (('airspeed', 'NN'), 'nmod', ('swallow', 'VB')), (('swallow', 'VB'), 'case', ('of', 'IN')), (('swallow', 'VB'), 'det', ('an', 'DT')), (('swallow', 'VB'), 'amod', ('unladen', 'JJ')), (('What', 'WP'), 'punct', ('?', '.'))]]
# Tokenizer
>>> parser = CoreNLPParser(url='http://localhost:9000')
>>> list(parser.tokenize('What is the airspeed of an unladen swallow?'))
['What', 'is', 'the', 'airspeed', 'of', 'an', 'unladen', 'swallow', '?']
# POS Tagger
>>> pos_tagger = CoreNLPParser(url='http://localhost:9000', tagtype='pos')
>>> list(pos_tagger.tag('What is the airspeed of an unladen swallow ?'.split()))
[('What', 'WP'), ('is', 'VBZ'), ('the', 'DT'), ('airspeed', 'NN'), ('of', 'IN'), ('an', 'DT'), ('unladen', 'JJ'), ('swallow', 'VB'), ('?', '.')]
# NER Tagger
>>> ner_tagger = CoreNLPParser(url='http://localhost:9000', tagtype='ner')
>>> list(ner_tagger.tag(('Rami Eid is studying at Stony Brook University in NY'.split())))
[('Rami', 'PERSON'), ('Eid', 'PERSON'), ('is', 'O'), ('studying', 'O'), ('at', 'O'), ('Stony', 'ORGANIZATION'), ('Brook', 'ORGANIZATION'), ('University', 'ORGANIZATION'), ('in', 'O'), ('NY', 'STATE_OR_PROVINCE')]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
中文:
>>> parser = CoreNLPParser('http://localhost:9001')
>>> list(parser.tokenize(u'我家没有电脑。'))
['我家', '没有', '电脑', '。']
>>> list(parser.parse(parser.tokenize(u'我家没有电脑。')))
[Tree('ROOT', [Tree('IP', [Tree('IP', [Tree('NP', [Tree('NN', ['我家'])]), Tree('VP', [Tree('VE', ['没有']), Tree('NP', [Tree('NN', ['电脑'])])])]), Tree('PU', ['。'])])])]
2
3
4
5
6