 七月NLP课程笔记(6)-深度学习与NLP应用
七月NLP课程笔记(6)-深度学习与NLP应用
ref: http://blog.csdn.net/zxm1306192988/article/details/78640443
# Intro
中英文处理的区别:中文需要专门进行分词,可以使用启发式方法(如,jieba),或者基于机器学习/统计的方法(如HMM、CRF等)
深度学习库:
- gensim–自然语言处理
- keras(keras.io)–底层是 theano 或 TensorFlow 框架
# Auto-Encoder
一种数据压缩方式,自动学习得到一个编码器。 主要可用于数据降噪、数据降维。
ref: http://blog.csdn.net/touch_dream/article/details/77500817 https://www.cnblogs.com/yangmang/p/7530463.html
# CNN4Text
卷积神经网络(CNN),因为其特殊的结构,在图像处理和语音识别方面都有很出色的表现。在图像处理中,对图像用一个卷积核进行卷积运算,实际上就是一个滤波过程。绿色表示输入的图像,可以是一张黑白图片,0是黑色像素点,1是白色像素点。黄色就表示滤波器(filter),也叫卷积核(kernal)或特征检测器(feature detector)。通过卷积,对图片的像素点进行加权,作为这局部像素点的响应,获得图像的某种特征。 在图像处理中,卷积操作可以用来对图像做边缘检测,锐化,模糊等。
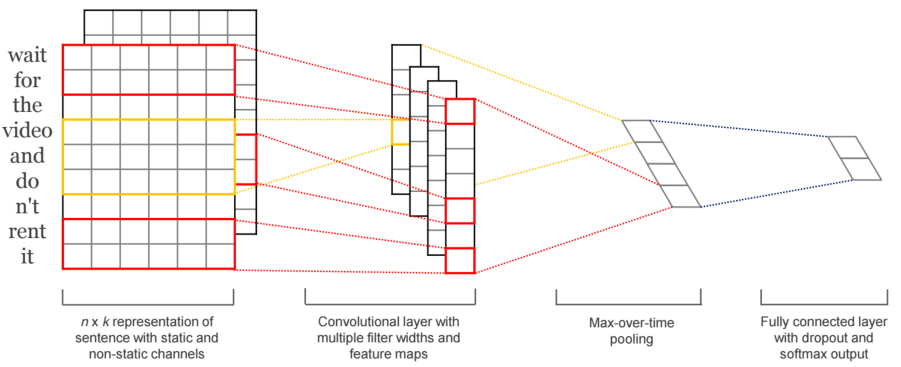
在文本处理中,使用word2vec,将文字转换为向量,从而一句话可以转换为类似图片一样的矩阵形式,进行卷积层处理(提取特征),进行max pooling处理(筛选特征),然后可用softmax进行分类。
# RNN
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。 RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
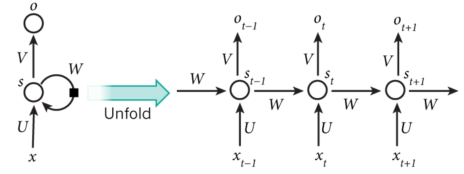
每个时间点中的S计算 st=f(当前输入+t-1时刻的记忆) 这个神经元最终的输出,基于最后一个时间点的s , ot=softmax(Vst)
简单来说,对于 t=5 来说,其实就相当于把一个神经元拉伸成五个 换句话说,s 就是我们说的记忆(因为把 t 从1-5的信息都记录下来了)
你可以认为隐藏层状态 st 是网络的记忆单元. st 包含了前面所有步的隐藏层状态。而输出层的输出 ot 只与当前步的 st 有关,在实践中,为了降低网络的复杂度,往往 st 只包含前面若干步而不是所有步的隐藏层状态;
传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么 xt 到 st 之间的U矩阵与 xt+1 到 st+1 之间的U是不同的,而RNNs中的却是一样的,同理对于 s 与 s 层之间的 W、s层与o层之间的V也是一样的。
上图中每一步都会有输出,但是每一步都要有输入并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关系最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs 的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
# LSTM
LSTM与一般的RNNs结构本质上并没有什么不同,只是使用了不同的函数去去计算隐藏层的状态。
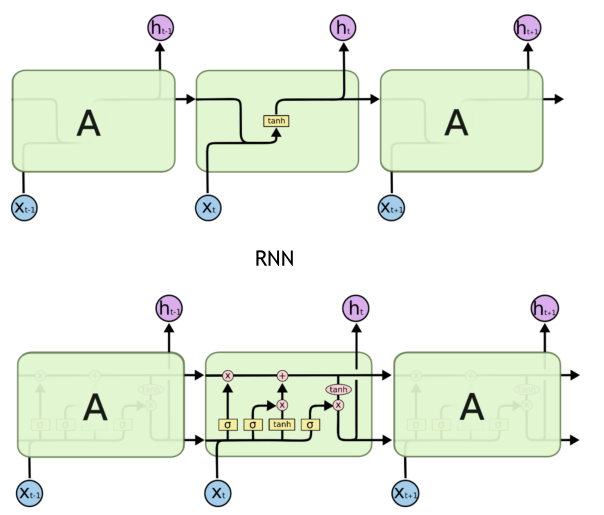
rnn只是将昨天的记忆和当前输入做了tanh的函数计算,但lstm具有更加复杂的神经元结构。
lstm具体的过程见开头的ref博客文章,包括忘记门、记忆门、更新门、输出门。
# 应用案例
用RNN做文本生成
char级别的文本生成,即给出前置的几个字母,预测下一个字母是什么?
import numpy
from keras.models import Sequential
from keras.layers import Dense #每个层级
from keras.layers import Dropout # 为了防止过拟合,忽略掉中间的一些神经元
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# 读入文本,用丘吉尔的人物传记作为学习预料
raw_text = open('input/Winston_Churchil.txt', encoding='UTF-8').read()
raw_text = raw_text.lower() # 都变成小写
chars = sorted(list(set(raw_text))) # 得到所有字符
char_to_int = dict((c, i) for i, c in enumerate(chars)) # 从字符到数字的对照表
in_to_char = dict((i, c) for i, c in enumerate(chars)) # 从数字到字符的对照表
print(len(chars)) # 61 个字符
print(len(raw_text)) # 276830 个字符
# 构造训练测试集
# 我们需要把我们的 raw_text 变成可以训练的 x,y
# x是前置字母们 y是后一个字母
seq_length = 100 # 一个 x 的长度,即根据前100个字符预测下一个字符
x = []
y = []
for i in range(0, len(raw_text) - seq_length):
given = raw_text[i:i + seq_length]
predict = raw_text[i + seq_length]
x.append([char_to_int[char] for char in given]) # 将字符存为词袋中的编号
y.append(char_to_int[predict])
print(x[:3]) # 查看前三条x
print(y[:3])
# 我们已经有了一个Input数字形式的表达,我们要把它变成LSTM需要的数组格式:[样本数,时间步伐,特征长度]
# 样本数是X一共有多少,时间步伐是记忆的长度,此题为100,特征是一个一个字符,所以是1
# 对于output,用 one-hot 做output 的预测可以给我们更好的效果,相对于直接预测一个准确的y数值的话。
n_patterns = len(x) # 训练集个数
n_vocab = len(chars) # 字符的个数
# 把x变成LSTM需要的样子
x = numpy.reshape(x, (n_patterns, seq_length, 1)) # [样本数,时间步伐,特征长度] 个人理解 :变成了一个样本数*时间步伐数*特征 的三维矩阵,每一行是一个样本,每一行的每个字符是一个特征
# 简单normal到0-1之间
x = x / float(n_vocab)
# output变成ont-hot
y = np_utils.to_categorical(y) # 变成 样本数*61 的矩阵,相应位置是1,表示是这个字符 ,其他位置都是0
print(x[11])
print(y[11])
# 构建模型
model = Sequential()
model.add(LSTM(128, input_shape=(x.shape[1], x.shape[2]))) # 128是神经元个数,input_shape=(时间步伐,特征长度)
model.add(Dropout(0.2)) # 随机遗忘掉20%的神经元,避免轻易的落入局部最优解
model.add(Dense(y.shape[1], activation='softmax')) # Keras中的一个普通神经网络称为Dense,Dense(输出数组的长度,激活函数)
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(x, y, nb_epoch=50, batch_size=32) # 每32个数据一起跑,跑50圈
# 验证模型效果
def predict_next(input_array):
x = numpy.reshape(input_array, (1, seq_length, 1)) #使用相同的方式,变成LSTM需要的数组格式
x = x / float(n_vocab) #归一化为0-1之间的数
y = model.predict(x)
return y
def string_to_index(raw_input):
res=[]
for c in raw_input[(len(raw_input)-seq_length):]:
res.append(char_to_int[c])
return res
def y_to_char(y):
largest_index=y.argmax() #取序列中最大数值的位置
c=in_to_char[largest_index]
return c
# 总的方法,传入初始文本,续写200个字
def generate_article(init,rounds=200):
in_string=init.lower()
for i in range(rounds):
n=y_to_char(predict_next(string_to_index(in_string)))
in_string+=n
return in_string
init='His object in coming to New York was to engage officers for that service. He came at an opportune moment'
article=generate_article(init)
print(article)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
另一个基于word级别的预测案例,见本文开头的博客文章。