 L1、L2正则化的区别
L1、L2正则化的区别
# L1,L2正则化
机器学习中, 损失函数后面一般会加上一个额外项,常用的是l1-norm和l2-norm,即l1范数和l2范数。
可以看作是损失函数的惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
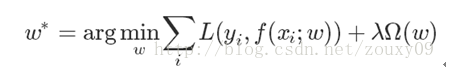 上面的目标函数,第一项是模型要最小化的误差,第二项是正则化项,λ>=0调节两者之间关系的系数。
上面的目标函数,第一项是模型要最小化的误差,第二项是正则化项,λ>=0调节两者之间关系的系数。
正则化项可以取不同的形式。
L0范数 是指正则化项是 参数矩阵W中非0元素的个数,也就是说希望W的大部分元素都是0,W是稀疏的。
由于L0正则项非连续非凸不可求导,难以找到有效解,转而使用L1范数。
L1范数 正则化项是向量中各个元素的绝对值之和。
L0和L1范数可以实现让参数矩阵稀疏,让参数稀疏的好处,可以实现对特征的选择(权重为0表示对应的特征没有作用,被丢掉),也可以增强模型可解释性(例如研究影响疾病的因素,只有少数几个非零元素,就可以知道这些对应的因素和疾病相关)
L1又称Lasso。
L2范数 功效是解决过拟合问题。当模型过于复杂,就会容易出现过拟合问题。
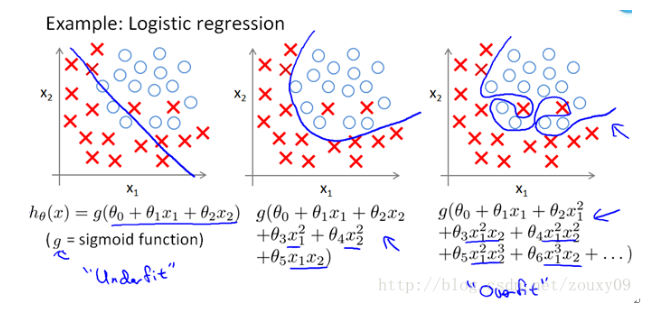
L2范数是指向量各个元素的平方,求和,然后再求平方根。 使L2范数最小,可以使得W的每个元素都很小,都接近于0,但和L1范数不同,L2不能实现稀疏,不会让值等于0,而是接近于0。一般认为,越小的参数,模型越简单,越简单的模型就不容易产生过拟合现象。
L2又称Ridge,也称岭回归。
# 小结
公式:
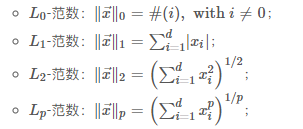
区别: 使用L1范数,可以使得参数稀疏化; 使用L2范数,倾向于使参数稠密地接近于0,避免过拟合。
# Reference
更多详细的公式,以及解释和分析,可参考
- 李航书
- 西瓜书
- https://liam0205.me/2017/03/30/L1-and-L2-regularizer/
- https://blog.csdn.net/zouxy09/article/details/24971995
- https://blog.csdn.net/vividonly/article/details/50723852
- https://blog.csdn.net/jinping_shi/article/details/52433975
上次更新: 2022/11/11, 2:11:00