 特征工程入门与实践 | 读书笔记
特征工程入门与实践 | 读书笔记
最近看了《特征工程入门与实践》这本书。因为是从外语翻译过来的,所以有的地方读起来稍微不那么流畅,但总体来说认真一点看还是能看懂的。

个人觉得这本书比较好的地方在于,对特征工程进行了一个比较系统和全面的梳理。能够让你明白说,拿到一份数据集之后,要想将它应用到机器学习模型中,这中间你需要做什么,有哪些点需要考虑。很多时候拿到数据可能会觉得无从下手,那么这本书就能提供很好的帮助。
书中对于涉及到的一些方法和概念,并没有深入讲解其原理,而是偏重于应用层面,你并不需要看懂复杂的公式,就能将这些方法运用起来。当然,建议还是要了解一下原理的,原理有更多专门的资料可以去查。
这本书以几乎手把手的方式,教你用 python、sklearn 等工具,来进行数据的处理。所以可以作为手边的参照,整理出你自己的一套常用数据处理代码来。
下面对章节主要内容做一个读书笔记。
# 1)特征工程简介
先讲了特征工程是什么,为什么要做特征工程。
特征工程(feature engineering)是这样一个过程:将数据转换为能更好地表示潜 在问题的特征,从而提高机器学习性能。
如何评估特征工程的效果呢?在应用特征工程之前,可以先用原始数据,应用到模型,得到一个基准性能;之后对数据应用特征工程,并用于模型中,看看性能指标相比基准是否有提升。
接下来的2-7章,将由浅入深来探讨特征工程的6个主要方面。
# 2)特征理解:我的数据集里有什么
这一章主要是拿到数据之后的第一步,对数据进行一些查看和探索性分析。例如,数据是结构化还是非结构化的?是定性的还是定量的?
通过sklearn工具,也可以对数据describe进行一些描述性统计,例如计算均值、方差、最大最小值、查看缺失值数量等。
本章提出了数据的四个等级:
定类等级:纯类别数据,例如人的血型、动物物种,人名等。可以进行一些计数、众数之类的操作。
定序等级:是类别数据,但类别间有次序。例如考试的成绩 (F、D、C、B、A)。可以引入比较和排序操作,计算中位数、百分位数等指标。
定距等级:定量数据,且有“距离”这一概念。例如温度,温差是有意义的。可以进行加减操作,因此可以计算平均数、标准差等指标。
定比等级:定量数据,且有绝对零点的概念,可以计算倍数,做乘除运算。例如,货币金额,有绝对的0元,且100元就是50元的两倍。上面提到的温度不是定比等级,因为温度没有绝对的零点,说100度比50度高一倍这种说法没有意义。
根据数据的不同等级,可以计算一些统计量,绘制一些图表对数据进行直观的观察。
# 3)特征增强:清洗数据
这一章开始清洗和增强数据,主要包括缺失值、归一化等处理。(主要针对定量数据)
识别缺失值:通过 pandas 的 isnull 方法可以检查是否有缺失值。但需要注意的一点是,有时数据集里的缺失值未必为 null,也许用 0 来填充了缺失值。仅仅依靠 isnull 是不行的,需要对每一列数据进行探索性分析,观察其均值、标准差、min max 值,是否和该列的实际含义有不符。
处理缺失值:一种办法是删掉缺失的行,但这样会导致丢失很多样本,也会破坏数据的分布。另一种办法是填充缺失值,可以用某个固定值填充,或者用该列的均值/中位数等来填充。注意:用均值填充时,计算均值应当仅根据训练数据来计算,不可以把测试集的数据也参与到计算均值里!
书中用到了 sklearn 中很方便的一些工具,例如 Pipeline 流水线,GridSearchCV 等,可以极大提升构建流水线、参数网格搜索的效率。
标准化和归一化:
z分数标准化,z = (x - μ) / σ,处理后数据服从均值为0标准差为1的标准正态分布。
min-max归一化,m = (x - x_min ) / (x_max - x_min ),处理后所有值都被缩放到0-1区间。
行归一化,前两种是对列的操作,这种是对行的操作,处理后使每一行的数据的L2范数都相同,也可以理解为,处理后每一行的向量的长度是相同的。
# 4)特征构建:我能生成新特征吗
分类特征的缺失值填充:可以用最常见的类别来填充缺失值。
分类特征的编码:对于定类等级,类别之间没有次序,用 one-hot 的方式来编码;对于定序等级,可以用顺序数值0、1、2 ... 来编码。
将连续特征分箱:例如将年龄分成年龄段
扩展数值特征:可以对数值特征进行特征交叉操作,捕获特征之间的交互关系,比如 abc三个特征,用二阶多项式交叉后,可以得到 a, b, c, ab, ac, bc, aa, bb, cc 等特征。
针对文本的特征构建:要将文本转换为数值特征才能放入模型。常见的是词袋法,不考虑词的顺序,构建 词-文档 矩阵,每一列是一个词,每一行是一条数据,值可以是原始计数,或者是 tf-idf 值。
# 5)特征选择:对坏属性说不
特征选择是从原来的特征中,只选出部分好的特征来保留,提升预测的性能。
预测的性能:既包括模型的评估指标(例如分类的准确率、回归的均方误差),也包括一些元指标(模型训练、拟合的耗时,模型的大小等)。通过比较性能差异,可以评估特征选择是否有效。
特征选择的方法可分为两大类。
基于统计的特征选择:通过一些统计方法来进行特征选择。皮尔逊相关系数,计算特征与响应变量y之间的相关系数,按相关系数由高到低选择部分特征;假设检验以“特征与响应变量没有关系”为假设,在一定的置信度下判断拒绝该假设的概率,保留与响应变量y有关系的特征。
基于模型的特征选择:训练一个额外的模型,通过这个模型中的一些参数来进行特征选择,例如决策树、带L1或L2正则化的逻辑回归,模型中的一些参数(例如LR中某个特征的权重w)能够表征出该特征的重要程度,保留重要的特征。
# 6)特征转换:数学显神通
这章的主要内容其实是降维方法,希望用更少的列来达到比之前相同甚至是更好的效果。
PCA主成分分析:无监督方法,目标是使得投影后的数据具有最大的方差。利用了协方差矩阵的特征值分解,保留具有高特征值的特征向量,用这个特征向量实现对原始数据的降维转换。
LDA线性判别分析:有监督方法,考虑了类别标签,降维过程中尽量不损失类别信息。目标是最大化类间距离,最小化类内距离,使得投影后的样本更容易分类开。
上面两个方法的具体数学原理和公式推导,需要参考其他资料。书中提供了 python 手动一步一步来做降维的步骤代码,也提供了使用 sklearn 库函数来降维的方法。
上面两种方法本质还是线性的转换,如果数据有非线性结构,上面的方法可能并不适用了,需要有更强大的工具。这就引出了第七章通过神经网络来学习特征。
# 7)特征学习:以AI促AI
这章讲了两种方法,分别是 受限玻尔兹曼机 和 词嵌入,都是无监督的学习。
受限玻尔兹曼机:是一个两层的神经网络,包括可见层和一个隐藏层,可见层的神经元个数等于输入的维度,隐藏层神经元个数可以自己定义,可以小于输入维度(相当于降维了),也可以大于输入维度。
其基本思路是,前向阶段通过 输入-可见层-隐藏层,得到输出a,重建阶段我们把方向反过来,根据之前的输出a,通过网络反向计算,希望能重建出原来的输入。经迭代之后,可以认为网络具有了从输入中提取特征的能力。
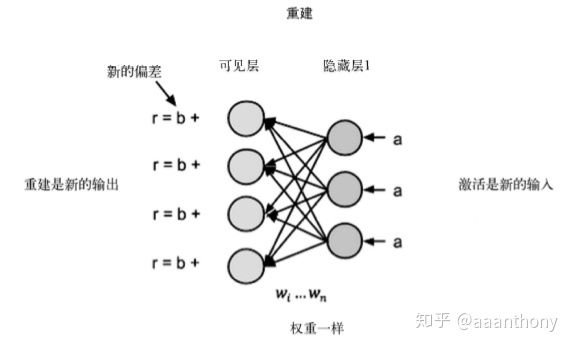
词嵌入:有 word2vec 和 GloVe 等方法来做词嵌入。word2vec 也是一个浅层的神经网络,在给定的窗口大小内,用一个词预测它周围的词,或者用它周围的词来预测中间的一个词。按此方法,网络参数可以学习得到各个词的 embedding 表示。
# 8)案例
通过面部表情识别、酒店评论文本的主题聚类,这两个案例来展示了本书前面讲的方法的实际应用。