 neo4j的Cypher查询语法笔记
neo4j的Cypher查询语法笔记
官方文档 : https://neo4j.com/docs/developer-manual/current/cypher/
# 语法
# 值和类型
- 字面量/属性值
- 节点、关系和路径
- map和list类型
# 命名
大小写敏感 node的类型名,建议以 PascalCasing relationship的类型名,建议以全大写命名 变量命名多为小写 还有一些保留关键字,如 true, false, null 等
# CASE语句
MATCH (n)
RETURN
CASE
WHEN n.eyes = 'blue'
THEN 1
WHEN n.age < 40
THEN 2
ELSE 3 END AS result
2
3
4
5
6
7
8
# 参数
构造查询时可以用 $param 占位填充参数,避免拼接字符串的麻烦。 Parameters.
{
"name" : "Michael"
}
2
3
Query.
MATCH (n:Person)
WHERE n.name STARTS WITH $name
RETURN n.name
2
3
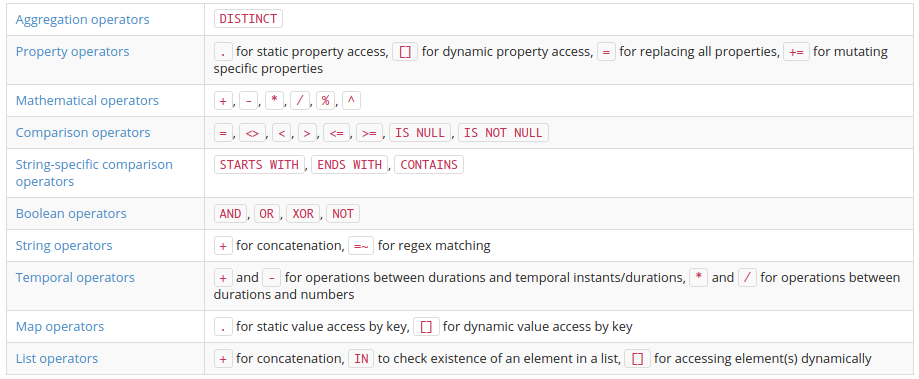
# 操作符
# 注释
使用双斜线 //
# 模式 Pattern
使用pattern来描述节点、关系和路径。
//表示节点和关系(支持加入类型和属性信息)
(a {name: 'value'})-[r:REL_TYPE]->(b)
//直接数字指定长度,而无需手写节点
(a)-[*2]->(b) 相当于 (a)-->()-->(b)
//长度可以是范围
(a)-[:KNOWS*3..5]->(b) // 用途:查找3-5度人脉
//不限长度
(a)-[*]->(b)
//定义变量来表示一条路径
p = (a)-[*3..]->(b)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 列表 List
// list 字面量:
//query
RETURN [x IN range(0,10) WHERE x % 2 = 0] AS result
//result
[0,2,4,6,8,10]
//query
RETURN [x IN range(0,10)| x^3] AS result
//result
[0.0,1.0,8.0,27.0,64.0,125.0,216.0,343.0,512.0,729.0,1000.0]
// list应用于查询中:
//query (查询由某人出演的所有电影的年份,返回值封装为列表)
MATCH (a:Person { name: 'Charlie Sheen' })
RETURN [(a)-->(b) WHERE b:Movie | b.year] AS years
//result
[1979,1984,1987]
//使用 collect 可以将数据整理为一个 list 列表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 映射 Map
// map字面量
RETURN { key: 'Value', listKey: [{ inner: 'Map1' }, { inner: 'Map2' }]}
// map应用于查询
//query
MATCH (actor:Person { name: 'Charlie Sheen' })-[:ACTED_IN]->(movie:Movie)
RETURN actor { .name, .realName, movies: collect(movie { .title, .year })}
//result
{movies -> [{year -> 1979, title -> "Apocalypse Now"},{year -> 1984, title -> "Red Dawn"},{year -> 1987, title -> "Wall Street"}], realName -> "Carlos Irwin Estévez", name -> "Charlie Sheen"}
2
3
4
5
6
7
8
9
10
# 其他
日期时间、null处理、三维空间距离的处理等部分略过。
# 查询语句
查询语句一览: https://neo4j.com/docs/developer-manual/current/cypher/clauses/
# MATCH
查找节点:
MATCH (:Person { name: 'Oliver Stone' })--(movie:Movie)
RETURN movie.title
2
查找关系:
MATCH (wallstreet { title: 'Wall Street' })<-[r:ACTED_IN]-(actor)
RETURN r.role
// 使用 relationships 列出路径中的所有关系
//下面语句查询和charlie共同出演电影的人,假设数据中找到两个人,则返回这两个路径,每个路径是一个list其中包含两条acted_in关系。
MATCH p =(actor { name: 'Charlie Sheen' })-[:ACTED_IN*2]-(co_actor)
RETURN relationships(p)
//result
[:ACTED_IN[0]{role:"Bud Fox"},:ACTED_IN[1]{role:"Carl Fox"}]
[:ACTED_IN[0]{role:"Bud Fox"},:ACTED_IN[2]{role:"Gordon Gekko"}]
2
3
4
5
6
7
8
9
10
查找最短路径(shortestPath, allShortestPaths):
//query 查找两人之间的无向最短路径,15步以内。
MATCH (martin:Person { name: 'Martin Sheen' }),(oliver:Person { name: 'Oliver Stone' }), p = shortestPath((martin)-[*..15]-(oliver))
RETURN p
//result
(1)-[ACTED_IN,1]->(5)<-[DIRECTED,3]-(3)
//添加WHERE筛选,要求不把父子关系考虑在内
MATCH (charlie:Person { name: 'Charlie Sheen' }),(martin:Person { name: 'Martin Sheen' }), p = shortestPath((charlie)-[*]-(martin))
WHERE NONE (r IN relationships(p) WHERE type(r)= 'FATHER')
RETURN p
//如有多条最短路径,上面的只会返回一条,可使用all返回全部
MATCH (martin:Person { name: 'Martin Sheen' }),(michael:Person { name: 'Michael Douglas' }), p = allShortestPaths((martin)-[*]-(michael))
RETURN p
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# OPTIONAL MATCH
用法类似于match,但会用null来填充找不到的值。
MATCH (a:Movie { title: 'Wall Street' })
OPTIONAL MATCH (a)-[r:ACTS_IN]->()
RETURN a.title, r
//result
a.title = "Wall Street"
r = <null>
2
3
4
5
6
# RETURN
对取出的值进行投影,并返回
// 使用 * 表示返回所有元素
MATCH p =(a { name: 'A' })-[r]->(b)
RETURN *
// 使用 labels 获取节点或关系的标签
MATCH (robert:Critic)
RETURN robert, labels(robert)
// 使用 AS 起别名
MATCH (a { name: 'A' })
RETURN a.age AS SomethingTotallyDifferent
// return 不仅可以返回节点、关系、路径,也可以支持用更多表达式来定义返回值!
MATCH (a { name: 'A' })
RETURN a.age > 30, "I'm a literal",(a)-->()
//result
a.age > 30 = true
"I'm a literal" = "I'm a literal"
a)-->() = [(0)-[BLOCKS,1]->(1),(0)-[KNOWS,0]->(1)]
// 使用DISTINCT去重
MATCH (a { name: 'A' })-->(b)
RETURN DISTINCT b
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# WITH
with相当于一个中转,收集处理前一个match的值,并用作后面使用
// 查询和david有关,且至少有一条出边的节点
MATCH (david { name: 'David' })--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
// 查询和Anders有关的节点,按姓名进行排序且只取top1,然后对这一个节点查找其关联节点并返回
// 这样相当于先取出并筛选了精确需要的数据,再以这一部分数据去提取相关信息,避免第一次时查出大量无用信息
MATCH (n { name: 'Anders' })--(m)
WITH m
ORDER BY m.name DESC LIMIT 1
MATCH (m)--(o)
RETURN o.name
2
3
4
5
6
7
8
9
10
11
12
13
# UNWIND
将list展开成一系列行的形式。
//query 先将列表展开,进行了去重,然后又collect成列表
WITH [1, 1, 2, 2] AS coll
UNWIND coll AS x
WITH DISTINCT x
RETURN collect(x) AS setOfVals
//result
[1,2]
2
3
4
5
6
7
# WHERE
WHERE可设置筛选条件,且WHERE是和MATCH同时进行筛选,而不是先MATCH出来再WHERE筛选。
基本用法:
MATCH (n)-[k:KNOWS]->(f)
WHERE k.since < 2000
RETURN f.name, f.age, f.email
MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
// exists 可判断是否存在
MATCH (n)
WHERE exists(n.belt)
RETURN n.name, n.belt
2
3
4
5
6
7
8
9
10
11
12
13
字符串和正则:
// 字符串支持 STARTS WITH、ENDS WITH、CONTAINS、NOT
MATCH (n)
WHERE n.name STARTS WITH 'Pet'
RETURN n.name, n.age
// 支持正则表达式
MATCH (n)
WHERE n.name =~ 'Tim.*'
RETURN n.name, n.age
// 要使用两个反斜杠来escape?
// 整个式子前缀 (?) 来表示整个式子大小写不敏感
MATCH (n)
WHERE n.name =~ '(?i)AND.*'
RETURN n.name, n.age
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
筛选pattern:
MATCH (n)
WHERE (n)-[:KNOWS]-({ name: 'Timothy' })
RETURN n.name, n.age
2
3
IN :
MATCH (a)
WHERE a.name IN ['Peter', 'Timothy']
RETURN a.name, a.age
2
3
# ORDER BY
order by默认升序,加入desc表示降序排列。 null在升序时排在最后,在降序时排在最前。
MATCH (n)
RETURN n.name, n.age
ORDER BY n.name DESC
2
3
# SKIP 和 LIMIT
skip表示跳过几行,limit表示返回几行。
// 返回第2,3行
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 1
LIMIT 2
2
3
4
5
6
# CREATE
创建节点:
// 创建节点。一次可创建多个,可加多个标签,可加属性,可在创建后返回此节点
CREATE (a:Person:Swedish { name: 'Andy' }) ,(m)
RETURN a.name
2
3
创建关系:
// 可以指定关系的标签(类型)和属性。
MATCH (a:Person),(b:Person)
WHERE a.name = 'A' AND b.name = 'B'
CREATE (a)-[r:RELTYPE { name: a.name + '<->' + b.name }]->(b)
RETURN type(r), r.name
2
3
4
5
创建整条路径:
// 创建3个节点和2条关系
CREATE p =(andy { name:'Andy' })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael { name: 'Michael' })
RETURN p
2
3
创建时可采用传参数占位的方式:
//参数
{
"props" : [ {
"name" : "Andy",
"position" : "Developer"
}, {
"name" : "Michael",
"position" : "Developer"
} ]
}
//语句
// UNWIND可以把列表展开,而SET则是用列表中的每个属性,覆盖n原来的属性。
UNWIND $props AS map
CREATE (n)
SET n = map
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# DELETE
用于删除节点、关系和路径 删除时如果节点有关系,必须显式删除关系,但如果用 DETACH DELETE则会自动删除相关关系。
MATCH (n { name: 'Andy' })
DETACH DELETE n
2
只删除关系,而不删除节点:
MATCH (n { name: 'Andy' })-[r:KNOWS]->()
DELETE r
2
# SET
set用于更新节点或关系上的属性和标签。
// 新增或更新属性
MATCH (n { name: 'Andy' })
SET n.surname = 'Taylor'
RETURN n.name, n.surname
// 也可以将一个map或另一节点的属性赋予当前节点。注意:当前节点的原有属性都将被清除。
MATCH (at { name: 'Andy' }),(pn { name: 'Peter' })
SET at = pn
RETURN at.name, at.age, at.hungry, pn.name, pn.age
// 某个属性set为null,或者整个节点set为{},可以实现删除属性的效果
// 使用 += 而不是 = ,可以实现属性的增补,即,原来没有的属性会新增,原来有的属性且有新值的属性会更新,原来有但新值没有指定的属性会保持原样
MATCH (p { name: 'Peter' })
SET p += { age: 38, hungry: TRUE , position: 'Entrepreneur' }
RETURN p.name, p.age, p.hungry, p.position
// set 也可以用来设置标签
MATCH (n { name: 'George' })
SET n:Swedish:Bossman // 设置了多个标签
RETURN n.name, labels(n) AS labels
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# REMOVE
与SET相对应,REMOVE可以移除标签和属性。
// 移除属性
MATCH (a { name: 'Andy' })
REMOVE a.age
RETURN a.name, a.age
// 移除标签
MATCH (n { name: 'Peter' })
REMOVE n:German
RETURN n.name, labels(n)
2
3
4
5
6
7
8
9
# FOREACH
// 使用nodes()提取路径中的节点,foreach为每个节点赋值
MATCH p =(begin)-[*]->(END )
WHERE begin.name = 'A' AND END .name = 'D'
FOREACH (n IN nodes(p)| SET n.marked = TRUE )
2
3
4
# MERGE
当节点存在时merge可以查找它,当节点不存在时merge可以创建并返回它,相当于create和match的结合。
// 先查找一个节点所在城市,如果城市存在则查找返回,如果城市不存在则创建返回
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
RETURN person.name, person.bornIn, city
2
3
4
5
可以分别指定创建还是查找节点时所进行的操作:
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
ON MATCH SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
2
3
4
merge也可以应用于对关系的操作。
// 首先要保证要match的person节点存在,然后merge查找或创建city节点,然后merge查找或创建borin关系
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
MERGE (person)-[r:BORN_IN]->(city)
RETURN person.name, person.bornIn, city
2
3
4
5
# UNION
可以将两个查询的结果合并起来
// 不加 ALL,可以去重
MATCH (n:Actor)
RETURN n.name AS name
UNION
MATCH (n:Movie)
RETURN n.title AS name
// 加 ALL, 如果有重复,包含重复
MATCH (n:Actor)
RETURN n.name AS name
UNION ALL
MATCH (n:Movie)
RETURN n.title AS name
2
3
4
5
6
7
8
9
10
11
12
13
# 其他
省略了以下部分的内容,详见文档: LOAD CSV CALL [...YIELD]
# 方法(函数)
支持的函数列表:https://neo4j.com/docs/developer-manual/current/cypher/functions/