 中文分词相关技术
中文分词相关技术
# 三大主要流派
- 基于词典:例如正向/反向/双向最大匹配、最小切分等。优点:速度快;缺点:歧义和未登录词(词典中没出现),效果不好。
- 基于语法和规则:分词时进行句法、语义分析,利用这些信息进行词性标注,来解决歧义现象。缺点:语言知识复杂,难以实现模拟人对句子的理解。
- 基于统计:基于语料库统计频率,较为主流,如N-gram、HMM、CRF、ME等模型。用词典匹配来分词,使用统计方法识别新词,一般两者结合,改善了歧义和未登录词的识别。也出现了基于神经网络的分词工具(Bi-LSTM + CRF)
# ICTCLAS的分词方法
ICTCLAS结合了词典和统计方法,较好地实现中文分词。
# 词典结构
(1)一元词典 例如 ”跳槽 vi 71 vn 55“,表示跳槽这个词,有两种不同词性,每种词性的出现次数。 (2)二元词典 bi-gram语言模型,例如 ”像@跳舞 4” 表示 像和跳舞 两个词前后出现,频次为4 (3)NER词典 NER词典相当于HMM模型的一些参数(转移概率和输出概率) 一元词典,即输出概率,例如,“ 郑 B 3505 C 21 E 20 D 5” 表示郑这个字,作为B姓氏出现3505次,作为C三字名的第二个字出现21次,作为D单字名的第三个字出现5次,作为E单字名出现20次…… 二元词典,即转移概率,是方阵的形式,例如A行B列表示从A的下一个是B类的频次。
人名、地名等NER词典的结构基本类似。
# 分词过程
按照如下步骤,进行分词。
1.句子切分 将篇章按照句号、逗号、分号等标点符号,拆分成句子处理。 如果篇章较大,可以切分后,多线程处理每个句子的分词。
2.一元词网 首先每个字作为一行,从每个字开始,向后组词查词典,能查到的话,就加到这个字的这一行,表示这个字可以组成某个词,同时记下词频和词性。 例如,“中华人民共和国”,生成 中 中华 华 华人 人 人民 民 共 共和 共和国 和 国 然后进行原子切分和类型确定,主要就是因为文本中有一些英文、中文、数字夹杂,通过对每个字查找其utf8编码范围,识别该字是否是英文、数字,对于英文数字,不应当切成单个字符,所以要通过这一步,把他们重组成词作为一个节点,而汉字可以每个字作为一个节点
一元词网大致样子:(乔布斯识别为人名是因为词典里有他,且标记词性为人名了)
0: [ 开始#开始 ]
1: [ 乔 乔 ] [ 乔布 人名 ] [ 乔布斯 人名 ]
2: [ 布 布 ]
3: [ 斯 斯 ]
4: [ 说 说 ]
5: [ iphone 英文 ]
……
2
3
4
5
6
7
3.二元词图 将一元词网中的节点,两两寻找他们之间的边权重。权重通过对起始点和bi-gram的词频加以计算得到。计算方法见论文3.2节 (opens new window)。按照这种计算方法,权重越小越好。
4.N-short寻找最短路径 类似Dijkstra算法 (opens new window)的一种N-Short方法。
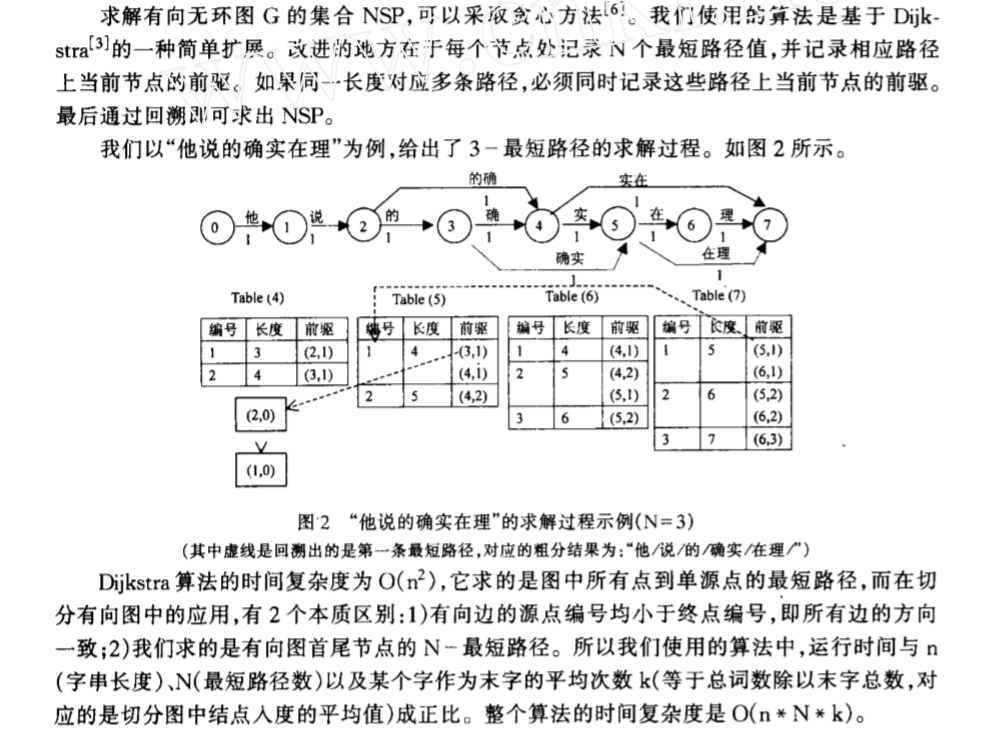
完成粗分阶段。
5.基于规则的后处理 基于一些中文规则,例如年月日模式,几点几分模式等等,加一些规则处理这些具有明显规律的特殊情况。
6.NER 使用HMM模型和Viterbi算法,结合NER词典,进行命名实体识别,将NER得到的一些结果,作为节点加入到一元词网中。然后重新构建词图,并用N-Short寻找最短路径,完成细分阶段的分词。
# 中文分词工具
# NLPIR (多语言)
NLPIR分词系统,前身为2000年发布的ICTCLAS词法分析系统
链接:https://github.com/NLPIR-team/NLPIR
由北京理工大学张华平博士研发的中文分词系统,经过十余年的不断完善,拥有丰富的功能和强大的性能。 NLPIR是一整套对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。 主要功能包括:中文分词,词性标注,命名实体识别,用户词典、新词发现与关键词提取等功能。
有第三方开发的PyNLPIR,Python版本 github链接: https://github.com/tsroten/pynlpir
论文: http://jcip.cipsc.org.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=1268
# jieba (python)
jieba的算法思想就是基于上面的ICTCLAS(N-Short)
jieba分词是国内使用人数最多的中文分词工具 github链接:https://github.com/fxsjy/jieba
jieba分词支持三种模式:
(1)精确模式:试图将句子最精确地切开,适合文本分析; (2)全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; (3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba分词过程中主要涉及如下几种算法:
(1)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG); (2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合; (3)对于未登录词,采用了基于汉字成词能力的 HMM 模型,采用Viterbi 算法进行计算; (4)基于Viterbi算法做词性标注; (5)基于tf-idf和textrank模型抽取关键词;
import jieba
#全模式
test1 = jieba.cut("杭州西湖风景很好,是旅游胜地!", cut_all=True)
#精确模式
test2 = jieba.cut("杭州西湖风景很好,是旅游胜地!", cut_all=False)
#搜索引擎模式
test3= jieba.cut_for_search("杭州西湖风景很好,是旅游胜地,每年吸引大量前来游玩的游客!")
2
3
4
5
6
7
# SnowNLP (python)
SnowNLP是一个python写的类库 https://github.com/isnowfy/snownlp 可以方便的处理中文文本内容,是受到了TextBlob的启发而写的 SnowNLP主要包括如下几个功能:
(1)中文分词(Character-Based Generative Model); (2)词性标注(3-gram HMM); (3)情感分析(简单分析,如评价信息); (4)文本分类(Naive Bayes) (5)转换成拼音(Trie树实现的最大匹配) (6)繁简转换(Trie树实现的最大匹配) (7)文本关键词和文本摘要提取(TextRank算法) (8)计算文档词频(TF,Term Frequency)和逆向文档频率(IDF,Inverse Document Frequency) (9)Tokenization(分割成句子) (10)文本相似度计算(BM25)
# THULAC (多语言)
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包
github链接:https://github.com/thunlp/THULAC-Python
具有中文分词和词性标注功能。THULAC具有如下几个特点:
(1)能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
(2)准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
(3)速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
# 哈工大LTP (C++,有py/java接口)
https://github.com/HIT-SCIR/ltp http://ltp.ai/index.html
# 斯坦福分词器
https://nlp.stanford.edu/software/segmenter.shtml
# Hanlp分词器 (Java)
https://github.com/hankcs/HanLP
# KCWS分词器(字嵌入+Bi-LSTM+CRF)
https://github.com/koth/kcws
# ZPar
https://github.com/frcchang/zpar/releases
# IKAnalyzer (Java)
https://github.com/wks/ik-analyzer
# Reference
https://blog.csdn.net/FlySky1991/article/details/73948971 https://www.zhihu.com/question/19578687