 检索技术笔记(3)系统案例篇
检索技术笔记(3)系统案例篇
检索技术是更底层的通用技术,它研究的是如何讲我们所需要的数据高效地取出来。
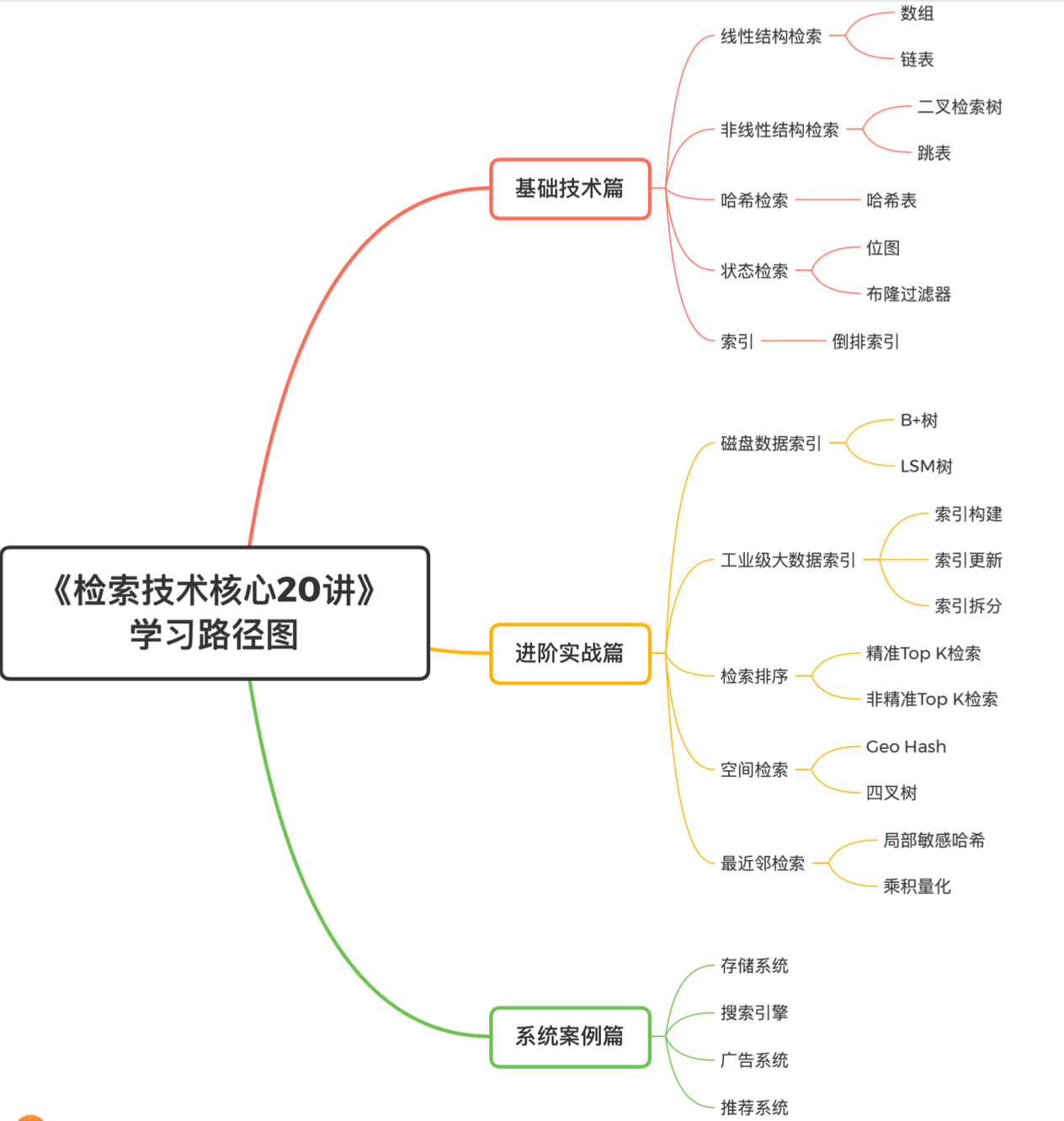
- 基础技术篇主要包括常见且核心的数据结构和检索算法
- 进阶实战篇主要结合工业界的应用场景,深入介绍一些高级检索技术和架构设计思想
- 系统案例篇对当前热门的应用方向进行分析
# 1. 存储系统:LevelDB
LevelDB是Google开源的存储系统,基于LSM树优化而来。
1) 读写分离,将内存数据高效存储到磁盘
使用跳表代替B+树,来实现内存中的C0树。
读写分离的设计,内存中的数据分为 MemTable 和 Immutable MemTable,当MemTable存储达到上限时,切为只读,并重新生成一个MemTable支持新数据的写入和查询。
合并时,采用延迟合并的设计,先将 Immutable MemTable 顺序快速写入磁盘,变成一个个 SSTable (Sorted String Table),然后再对这些 SSTable 文件进行合并。避免了C0和C1树合并的昂贵代价。
2)SSTable 的分层管理设计
SSTable 文件也要进行合并,采用多路归并的方式。合并后,需要保证文件之间的数据范围不重叠,这样查找时可以定位到某个文件完成查询。所以,当新增 SSTable 时,我们找出跟这个范围有重合的所有 SSTable,进行多路归并。同时,一个 SSTable 的大小是有限制的,所以多路归并的结果是多个 SSTable。
采用分层的方式,滚动合并,来避免大量数据的无效复制。从 Immutable MemTable 写进来的 SSTable 会被放在 Level 0 层,这一层满了之后,进行多路归并,放到 Level 1层,以此类推。每一层的容量有上限,满了之后就合并到下一层,而且容量上限逐层扩增。
为避免发生在下层的合并仍然产生大量开销,不仅会限制每个 SSTable 的大小,也会限制它跟下一层数据的重合度,如果重合超过了10个文件,则结束这个 SSTable 的生成,这样保证了每一个 SSTable 要和下层归并时,最多只涉及10个文件。
(为什么层的上限是容量而不是文件数量,也就是因为上面的限制可能会造成一层有很多个小的 SSTable 文件。所以用容量限制更好)
3)查找
Level 0 层是原始写入,因此这一层的每个文件都要查找。而之后的每一层,由于都经过了合并,保证覆盖范围是不重合的,所以可以先找到 SSTable 文件,再在文件中查找。找不到就继续沉入下一层。(如果找到了就没必要往下沉了,因为越往下是越旧的数据,即使存在相同key的,也只关心更新的数据)
4) SSTable 文件中的检索加速
SSTable 分为索引区和存储区,可以先将索引区读入内存,借助预先构建的布隆过滤器,快速判断这个文件中是否包含要找的数据,如果包含,则从索引中查找数据,然后读存储区,找到具体数据内容。
5)缓存机制
可以用 LRU 机制,将最近使用的数据和索引缓存到内存。
# 2. 搜索引擎
搜索引擎的核心系统包括爬虫系统、索引系统和检索系统。
- 爬虫系统:完成持续的网页抓取
- 索引系统:
- 网页预处理:相似网页去重,网页质量分析,分词,反作弊分析
- 生成索引:
- 索引拆分:分离出高质量和普通质量的网页,分别做索引;也需要基于文档进行拆分
- 索引构建:生成倒排
- 索引更新:全量结合增量,也采用滚动合并
- 检索系统:
- 查询分析,找出用户真实意图
- 拼写纠正或者相关查询推荐
- 召回+打分排序 Top K
查询分析
查询分析包括分词粒度(中文特有,比如按词,短语,字)、属性分析(权重分析、紧密度分析)和 需求分析(意图分析、时效性分析)
查询纠错
- 错误判断:人工和日志挖掘,得到常见字典和混淆字典;或者基于语言模型和机器学习;
- 候选召回:预估出每种出错的可能性,召回一些正确结果(比如发音相近,字形相近等)
- 打分排序
查询纠错和查询推荐不同。查询推荐更多是分析搜索日志的结果,分析哪些检索词之间有相关性。
短语检索
首先可以拿完整短语查询,如果结果足够多,就满足要求。否则,可以把短语拆分,然后对结果求交集。但是需要注意,需记录每个词在文档出现的位置,短语拆出来的几个词位置要相近,不能太远,可以按照这个信息来对结果进行排序。
# 3. 广告系统
整体架构
广告可以分为搜索广告和展示广告。搜索广告是关键词输入后,在结果中返回;展示广告则是在搜索引擎之外,比如打开某些app时出现的广告。搜索广告中,广告和搜索词有很强的相关性,类似于搜索;而展示广告,没有搜索词的约束条件,更加灵活。
通过系统对用户的长期行为收集和分析,可以知道用户的喜好,打上标签;各种网页和广告位,也可以有网页分类等标签信息。另一方面,广告主在投放时,也会加上一些定向投放的条件。所以,广告引擎处理一个广告请求的过程,是根据用户的广告请求信息,找出匹配的广告,并进行排序返回的过程。还需要采集广告的后续监测数据,比如是否展现,是否点击等。
标签检索
以标签为key来对广告做倒排索引。比如“地域:北京”,前一半表示定向类型,后一半表示该类型下的具体标签取值。
有一些区分度很低的标签,比如“媒体类型:APP”,会包含大量广告,这类可以用tf-idf值的方式找出这种标签,不建倒排。但是在召回广告之后,需要用这些标签信息进行过滤,要满足广告主定向投放的要求。
对于区分度很低的标签,也可以作为树的结构,每一层是一个类型,不同取值代表不同分支,这样来建立分片索引,比如媒体类型、性别、操作系统这种,属于区分度很低的标签,但可以将索引划分成不同的片,进行分流。
向量检索
广告引擎自动召回,可以将广告和用户兴趣都表示为向量,做最近邻检索。
打分排序 分为召回、粗排、精排等阶段。不过广告最后通常只返回第一个结果。
索引精简 广告的生命周期变化非常快,比如预算用光了就不能再投出去了。而且由于广告总量小(相比推荐和搜索的候选池非常大),可以较快更新索引,因此也可以在索引中直接将不符合条件的广告过滤掉,而不是召回之后再过滤,节省索引空间。
# 4. 推荐系统
整体架构 搜索引擎中的强约束条件是用户输入的搜索词,广告系统中的强约束条件是广告主设置的定向要求,但在推荐引擎中,外界输入的检索约束条件非常少,推荐引擎有更灵活的检索能力。
在离线缓解,通过数据挖掘每个用户的星球,对用户分类,生成用户画像。在用户画像中,有着不同的标签,标签权重会随着时间变化衰减。同时,也会给文章打上标签。
召回 召回可以是基于统计的静态召回,比如离线统计好哪些点击量高、收藏多的热门文档等。也可以是个性化召回。
基于内容的召回:文章内容有标签,用户有兴趣标签,匹配。优点是不需要其他用户数据,也可以给出小众用户的推荐,新的文章加入后可以推荐;缺点是依赖用户和文章画像,难以挖掘用户的潜在兴趣,同时对一个冷启动新用户没有兴趣标签,无法给出推荐。
基于协同过滤的召回:又可以分为基于用户的协同过滤和基于物品的协同过滤。也可以将一部分计算放在离线环节。基于物品的协同过滤更注重兴趣传承,基于用户的协同过滤则更注重社会化的推荐,因此前者更倾向于商品电商,后者更适合于新闻资讯。
混合推荐 召回阶段有多路召回,混合使用各种方案;然后经过粗排、精排打分排序。