 检索技术笔记(1)基础技术篇
检索技术笔记(1)基础技术篇
检索技术是更底层的通用技术,它研究的是如何讲我们所需要的数据高效地取出来。
- 基础技术篇主要包括常见且核心的数据结构和检索算法
- 进阶实战篇主要结合工业界的应用场景,深入介绍一些高级检索技术和架构设计思想
- 系统案例篇对当前热门的应用方向进行分析
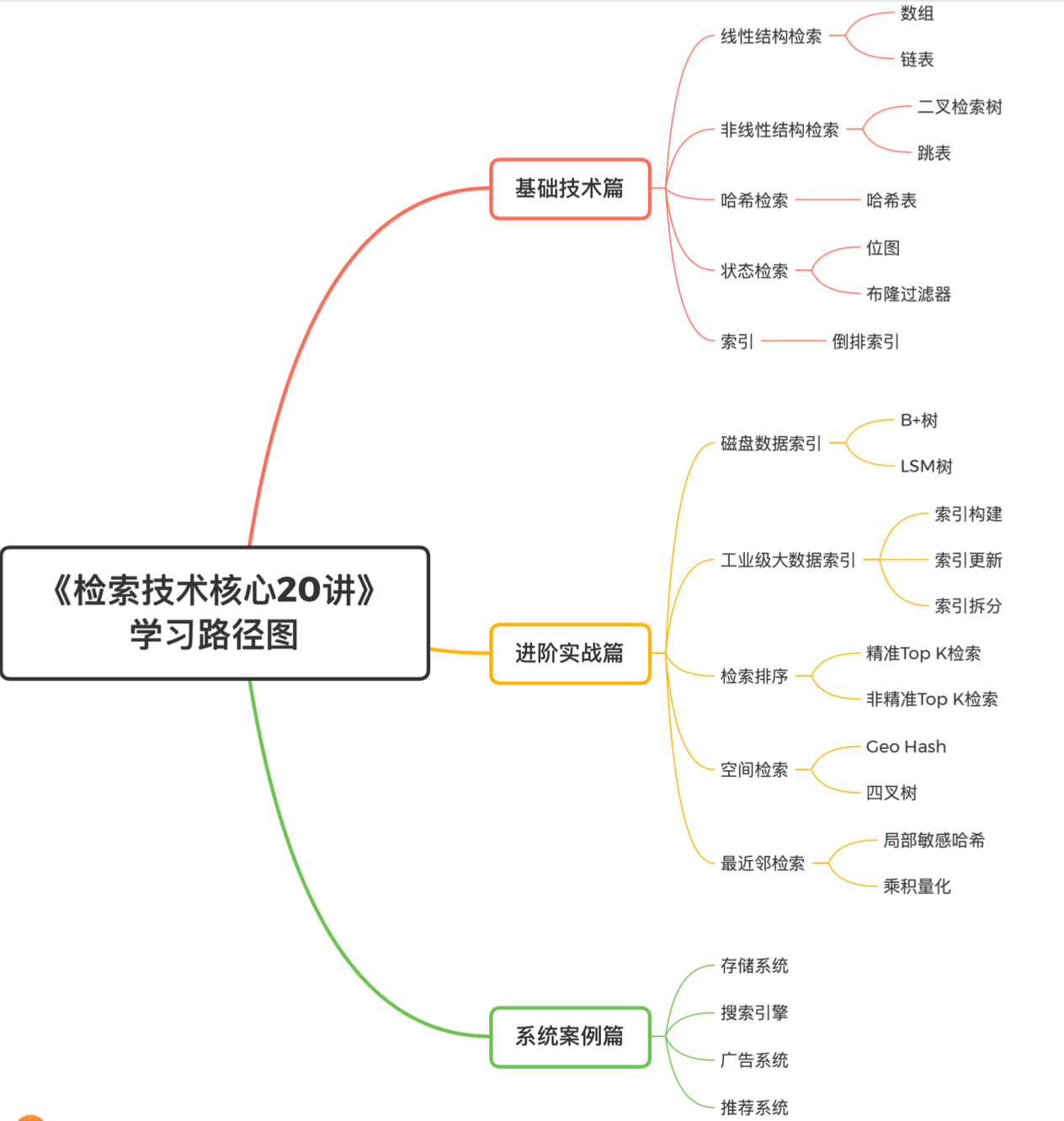
# 1. 线性结构检索
数组:有序数组可以通过二分查找提高检索效率
链表:检索能力偏弱,动态调整更容易。
# 2. 非线性结构检索
二叉搜索树(BST):通过平衡二叉搜索树或者红黑树结构,可以维持较好的左右平衡
跳表:在跳表中插入元素时,随机决定在哪些层新增连接关系,来维持跳表较好的平衡。
# 3. 哈希检索
哈希冲突的解决办法:
- 开放寻址法
- 线性向后探查,找到下一个空位
- 二次探查,探查步长x2
- 双散列,两个散列函数来计算位置
(需注意,开放寻址法删除元素时,需要置deleted标记而非直接删除,否则影响正确性。在数据动态变化多的情况下不太适合。——
- 链表法。如果短的话可以用链表,长的话可以转换为红黑树或者跳表(Java中的HashMap就是如此)
哈希表的缺点是为避免冲突,不能装太满,会浪费一些存储空间。
# 4. 状态检索(判断一个元素是否存在)
应用:比如要检查一个id是否在名单中,爬虫判断一个网站是否抓取过。
数组/位图:简单的方案可以寻找元素和数组下标的映射,使用数组来记录;也可以进一步缩小空间,用bit位来记录。会浪费空间,尤其是下标分散不连续的情况下。
使用布隆过滤器。
- 设置多个哈希函数,名单中的id使用每个哈希函数进行哈希,根据结果会把对应的位设置为1。当新id来的时候,也用所有哈希函数进行哈希,检查对应的位是否都为1, 是的话才认为在名单中。
- 缺点是在小概率下会存在误判的情况,将不在名单的元素认为在。可以通过调整哈希函数的个数,调节错误率。
- 布隆过滤器无法删除元素(也可以采用各个位不是存01而是存引用计数的布隆过滤器,但是会更复杂和占空间一些)
# 5. 倒排索引
正排:以 id 为 key,存储文章内容; 倒排:以 关键词 为key,存储文章 id。
查询同时包含 你 和 好 两个字的文档?取出两个关键词的倒排索引,如果有序的话,可以用合并两个有序链表的方式来查找两个倒排里共同包含的文档 id。
上次更新: 2022/11/11, 2:11:00